Are spreadsheets databases?
Nov 28 2020 · Databases
A few weeks ago, news that using Excel resulted in the loss of ~16,000 coronavirus cases in England due to a 65K row limit in XLS files, sparked a number of tweets around how Excel isn’t a database. There’s a lot to cringe at here, but saying Excel or, more precisely, spreadsheets aren’t databases and using a “proper database” would have prevented a failure is incredibly reductive.
Definition
To start, it’s worth looking at what the definition of “database” actually is:
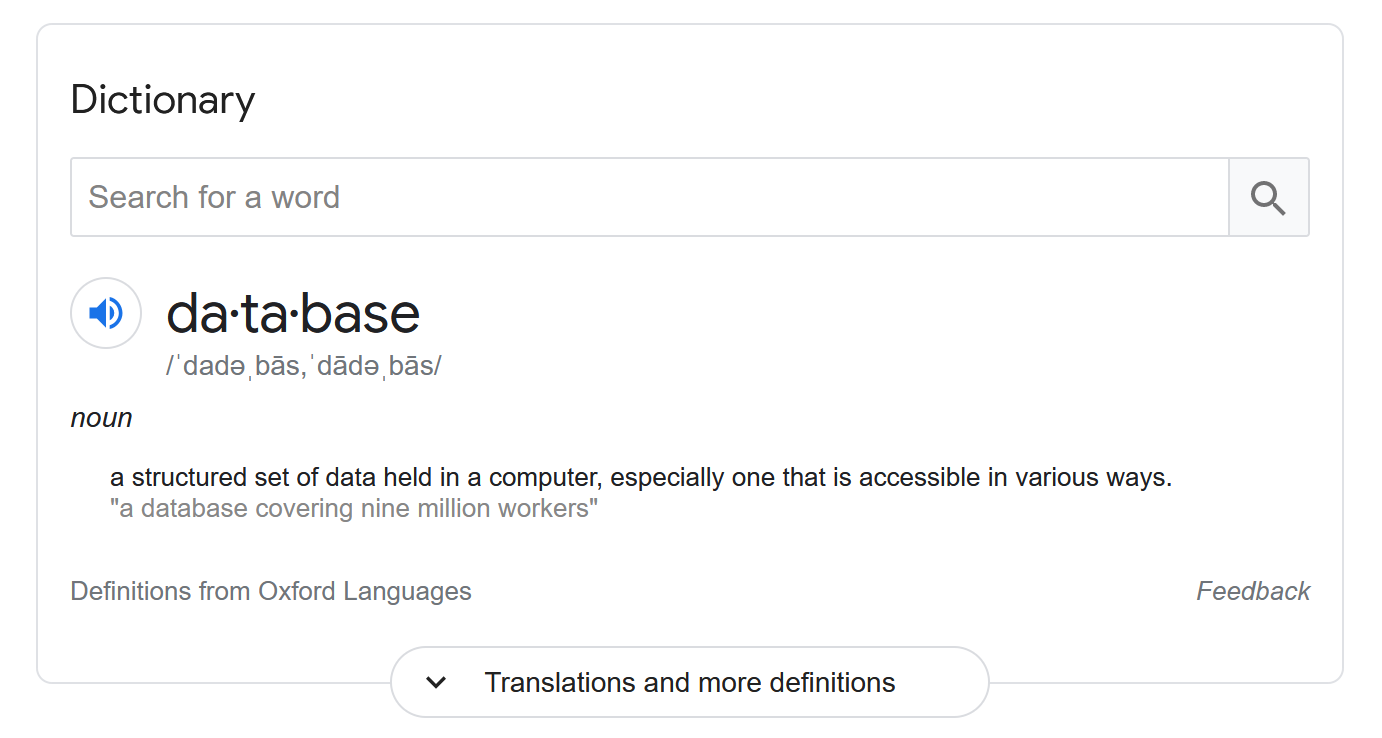
At least from that definition, I think it’s fair to say spreadsheets are databases. They’re primitive, there’s little-to-nothing in the way of concurrency, security, constraints, etc., but they are databases.
In software engineering, the term “database” is typically shorthand for a relational database, but that feels more and more problematic, as we now see many more databases in use now that aren’t relational (Cassandra, Mongo, DynamoDB, etc.). Even S3 now serves as a foundational basis for many databases.
System Considerations
Beyond definitions, what’s also interesting here is that tooling and database choice is never a simple equation for a non-trivial data system; there’s a host of considerations that come into play. Here’s a few that pop into my mind:
- Interfacing: Who’s accessing and/or manipulating data in the system? Sophisticated data systems and bespoke interfaces are powerful, but they require training and expertise, and there’s typically a higher maintenance burden. Leveraging common and ubiquitous tooling can be beneficial when it comes to interfacing needs for a larger audience. This comment on ArsTechnica points out that the “proper tools” are inordinately complex and not something a typical end-user can pick-up and understand easily, and I think that’s a fair assessment of the product landscape.
- System limits: every data system has limits, some are explicit and obvious, some are not. It’s also not surprising to bump into limits due how a database is setup or how a schema is designed. Hitting a 65K row limit is frustrating and problematic, but so is discovering a value is truncated because the field length was set too small or an incorrect type was used.
- Cost: What is the cost of the technical infrastructure? What about the cost of the people needed maintain the system? Unsurprisingly, more sophisticated and complex systems will cost more.
- Failure modes: What are some common ways this system fails? What does it take to recover and get back to normal operations? With simple systems you tend to just hit hard limits, but more complex systems fail in a multitude of ways.
- Time: When does this need to be shipped and what compromises need to be made? When you don’t have weeks or months to design and prototype, leveraging per-existing and proven method is typically the path of least resistance.
It’s perhaps easy to point to some of the issues that come into play with Excel and spreadsheets, but any data system will have its fair share of limits and risks, along with any potential benefits.







