MutationObserver, along with its siblings ResizeObserver and IntersectionObserver, are great tools for working with the DOM. I don’t think there’s necessarily broad usage of these observers in frontend development but, when building applications that need insight into lower-level DOM changes, they are powerful interfaces and allow you to avoid the typical/hacky solution of polling for changes.
Interface
All the observer classes share a common, fairly simple interface. There’s just a few key aspects needed to use them:
The constructor takes a callback, which is called whenever the DOM state change corresponding to the class (mutation, resize, etc.) is observed.
The observe() method takes a target DOM element to observer
On an observed state change (e.g. mutation) the given callback is called with an appropriate record (e.g. MutationRecord)
Missing context
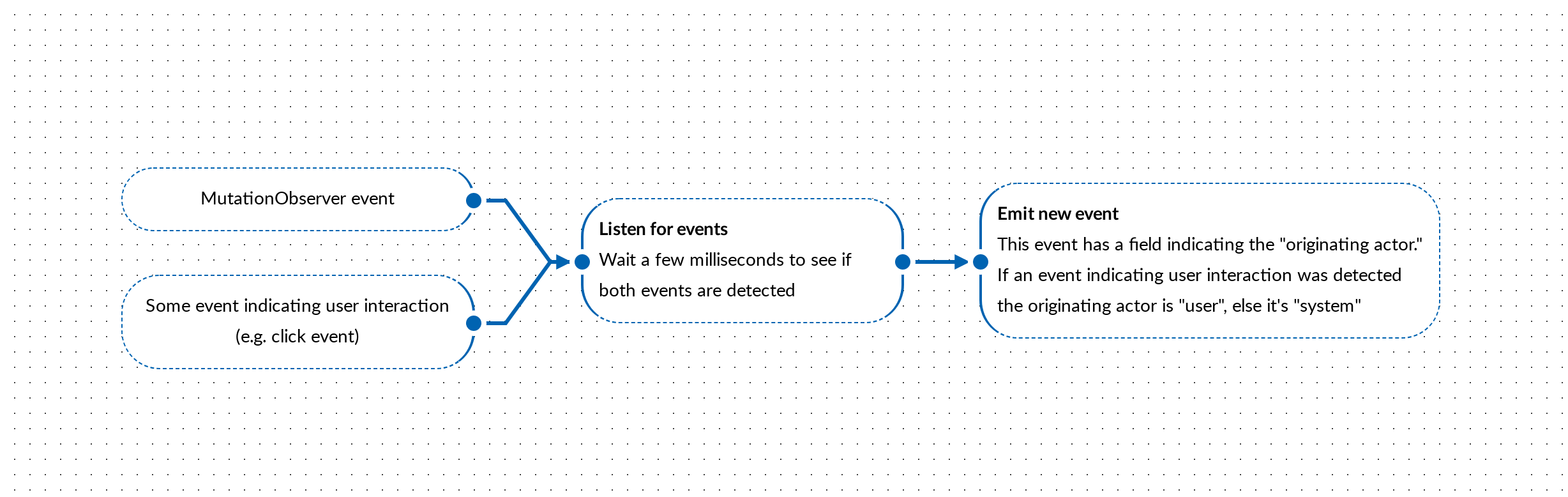
The records surfaced on an observed state change contain information about the change but nothing around who or what triggered the change. Looking at a comparable scenario, this is typically the case for most DOM events as well, but it’s generally a non-issue because you can reasonably assume that the event was triggered by the user interacting with the browser. When it comes to changes detected by an observer, there’s a bit more ambiguity as to how the change came about and you can’t always assume the change was from the end-user.
Note: yes, you an programmatically force DOM events to be emitted as well (e.g. element.click()) but I think this is almost always an anti-pattern
For example, let’s say you have an application where you allow users to enter content into a contenteditable <div> but you’d also programmatically surface and incorporate content coming from the server (from other internet users using the application). Ideally, you could use a MutationObserver on the <div> to detect changes and see if there’s new content that needs to be sent to the server, but you’d need to distinguish:
What changes are coming from the user interacting with the browser
What changes are being made programmatically (i.e. coming from other server / coming from other users)
Unfortunately, you can’t make this distinction with the information surfaced in a MutationRecord.
While DOM events don’t necessarily map to an actor model, I tend to think what’s conceptually missing here is knowing the originating actor of the events/message and, in any user-facing system, there’s going to be at least 2 actors:
The system
The end-user interacting with the system
Once you’re within a system dealing with mutating state, knowing who the originating actor is incredibly valuable information.
Hacking around this
I’m prototyping a hacky, but reasonable, solution for ScratchGraph:
Overall, this seems to work but I hate patterns like this where I have to purposely introduce latency.
Content from a web server being automatically gzipped (via apache, nginx, etc.) and transferred to the browser isn’t anything new, but there’s really nothing in the way of compression when going in the other direction (i.e. transferring content from the client to the server). This is not too surprising, as most client payloads are small bits of textual content and/or binary content that is already well compressed (e.g. JPEG images), where there’s little gain from compression and you’re likely to just waste CPU cycles doing it. That said, when your frontend client is a space for content creation, you’re potentially going to run into cases where you’re sending a lot of uncompressed data to the server.
Use-case: ScratchGraph Export
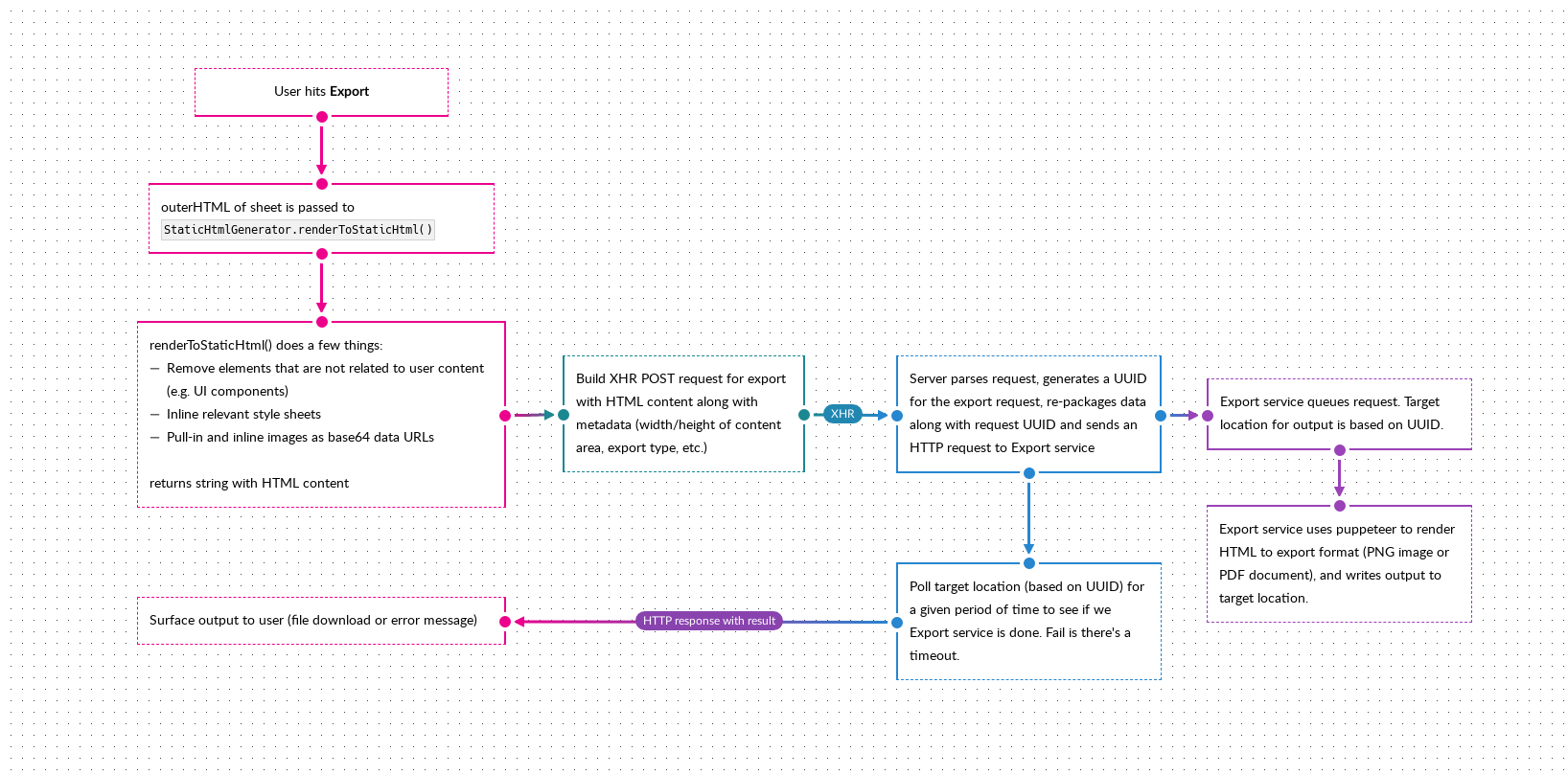
ScratchGraph has an export feature that essentially renders the page (minus UI components) as a string of HTML. This string packaged along with some metadata and sent to the server, which sends it to a service running puppeteer, that renders the HTML string to either an image or a PDF. The overall process looks something like this:
The HTML string being sent to the server is relatively large, a couple of MBs, due to:
The CSS styles (particularly due to external resources being pulled in and inlined as base64 URLs)
The user simply having lots of content
To be fair, it’s usually the former rather than the latter, and optimizing to avoid the inlining of resources (the intent of which was to try and do exports entirely in the browser) would have a greater impact in reducing the amount of data being transferred to the server. However, for the purposes of this blog post (and also because it leads to a more complex discussion on how the application architecture can/should evolve and what this feature looks like in the future), we’re going to sidestep that discussion and focus on what benefits data compression may offer.
Compression with pako
I was more than ready to implement a compression algorithm, but was happy to discover pako, which does zlib compression. Compressing (i.e. deflating) with pako is very simple, below I encode the HTML string to UTF8 via TextEncoder.encode() (this is because I want UTF8, this isn’t a requirement of pako), which returns a Uint8Array, then use that as the input for pako.deflate(), which also returns a Uint8Array.
const staticHtmlUtf8Arr = (new TextEncoder()).encode(html);
const compressedStaticHtmlUtf8Arr = pako.deflate(staticHtmlUtf8Arr);
Here’s what that looks like in practice, exporting the diagram shown above:
That’s fairly significant, as the data size has been reduced by 1,237,266 bytes (42.77%)!
The final bit for the frontend is sending this to the server. I use a FormData object for the XHR call and, for the compressed data, I put append it as a Blob:
formData.append(
"compressedStaticHtml",
new Blob([compressedStaticHtmlUtf8Arr], {type: 'application/zlib'}),
"compressedStaticHtml"
);
Handling the compressed data server-side with PHP
PHP support zlib compression/decompression via the zlib module. The only additional logic needed server-side is calling gzuncompress() to decompressed the compressed data.
Note that $compressedStaticHtmlFile is an object representing a file pulled from the request (note that FormData will append a Blob in the same manner as a file, so server-side, you’re dealing with the data as a file). The File.getFilePath() method here is simply returning the path for the uploaded file.
Limitations
Compressing and decompressing data will cost CPU cycles and, for zlib and most algorithms, this will scale with the size of the data. So considerations around what the client-side system looks like and the size of the data need to be taken into account. In addition, compression within a browser’s main thread can lead to UI events, reflow, and repaint being blocked (i.e. the page becomes unresponsive). If the compression time is significant, performing it within a web worker instead would be a better path.
A proper way to deal with clipboard access has been a dream for web developers for years. There’s out-of-the-box browser support, via keyboard shortcuts and content menu commands, for <input>, <textarea>, or elements with the contenteditable attribute. However, for more complex interactions or dealing with application-defined, non-textual objects (e.g. something composed of multiple DOM elements that is manipulable by the user, such as the ScratchGraph notes and connectors shown below) we need to start looking at the available Javascript APIs.
Clipboard API vs document.execCommand() + paste event
The bad news is that document.execCommand() (using the “cut”, “copy” commands) is still the de-facto way of writing to the clipboard, despite this method being deemed obsolete. The good news is that there does seems to be good progress, in terms of stability and browser implementation, of the Clipboard API.
For reading from the clipboard, the paste event seems to be the best way to go, however there is the inherent limitation that this event will only be triggered by “paste actions” from the browser’s interface (e.g. the use hitting Ctrl + V). Again, there is good news in that the Clipboard API would allow more flexibility here and there is good progress towards browser support.
Despite the good news around the Clipboard API, given the state of where things are now, in September 2020, using document.execCommand() and the paste event seems to be the way to go; the Clipboard API, as well as the corresponding permissions via the Permissions API, are still in the process of being implemented in browsers. However, most of what’s in this post will (hopefully) still be valid with the Clipboard API, with the clipboard interaction code being more robust and the more hacky bits being thrown away.
Copying to the clipboard with document.execCommand(“copy”)
Selecting plain text and copying it to the clipboard is straightforward with an <input> or <textarea>:
We can make a generic method to copy arbitrary text to the clipboard by programmatically creating a <textarea>, setting its value to the text we want, performing the above operations to copy its contents to the clipboard, and finally removing the created <textarea>.
Now, using this method, if we can serialize an object to some sort of textual format, we can put it on the clipboard. JSON is a good option, as it’s easy to work with in Javascript.
Object → JSON → Plain text → Clipboard
In ScratchGraph, entities like notes, connectors, etc. have a toJSON() method, which returns a JSON serialized representation of the entity, e.g.:
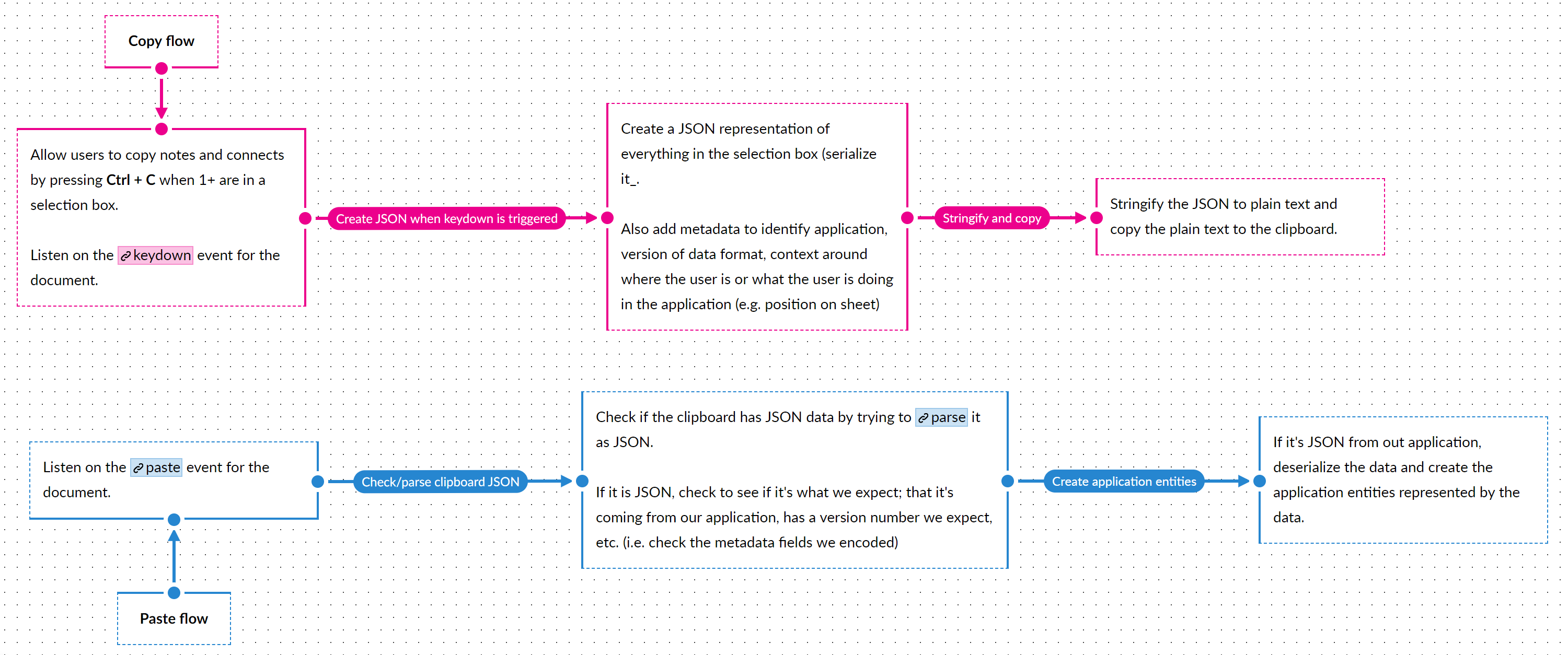
When a user initiates a request to copy something, say by hitting Ctrl + C, we iterate over all the selected entities, get the serialized JSON for each, and build an array of JSON objects. Next we construct a JSON object containing that array, along with some metadata around context (application name, version, etc.). Finally, we JSON.stringify this object to get a plain text representation and use the Clipboard.copyText() method to write to the clipboard.
To read what’s on the clipboard, we can listen for and implement a handler on the paste event.
While you can listen for the paste event on any DOM element, I’ve found it tricky to isolate to specific elements because the element that has focus isn’t always obvious and I’ve run into situations where an offscreen <input> gets focus and the clipboard content simply gets pasted into that input. It’s more reliable to listen on the document and determine if and where to paste something based on the metadata embedded when we copied data to the clipboard.
Sketching out what we need to deal with, we get the following:
Listen for paste events on the document
Check if there’s plain-text content being pasted
Try to parse the plain-text content as JSON
Check whatever metadata is in the object to see if it’s something copied from our application and it’s something we can read/interpret.
If it’s something we can handle, suppress any default behavior and do what is needed to clone and create new objects.
This is simplified for clarity, but the code in ScratchGraph looks something like this:
The createFromClipboardJson() method handles the application-specific logic of reading the data and creating copies. In ScratchGraph, I’m dealing with entities, so I don’t actually deserialize, I just read the bits of data needed to be make a clone and create something with a new ID (i.e. new entity). However, YMMV, based on the type of objects you’re dealing with, how your application handles data, and/or how you deal with state.
Limitations and future work
As I mentioned, there are limitations here when it comes to reading or writing from/to the clipboard. The paste event will only be triggered by interactions supported by the browser, so creating something like a button to paste content isn’t possible. document.execCommand("copy") is now considered obsolete and the method presented to allow copying arbitrary bits of text is pretty hacky, though it is versatile in that you can bind the method to application-specific interactions (e.g. a button to copy content). A further limitation here is that data can only be copied as plain-text and we’re not actually encoding any type information; this manifests in some non-ideal behavior, where what’s put on the clipboard can be pasted into any application that accepts plain-text.
The Clipboard API looks to be a promising solution to these limitations. I’m hoping to revisit this in the near future to update the clipboard interaction logic to use the API and have an all-round cleaner and more robust solution.
The Canvas API is surprising versatile. The image parameter of the CanvasRenderingContext2D.drawImage() method will accept images from a number of different sources including an HTMLVideoElement. I touched on this a bit in a previous post about processing the data from video streams, however HTMLVideoElement can also handle loading and rendering video files, with all modern browsers capable of tackling the non-trivial tasks of decoding and rendering H.264 MP4 or VP8/VP9 WebM content (and, of course, you get all the benefits of the client’s GPU hardware that the browser takes advantage of). This opens up the possibility of capturing frames from video files which can be used for preview images, poster images, or substituting in an image when video playback isn’t possible (e.g. for a print layout, which is the issue I’ve run into with ScratchGraph).
Setting up the HTMLVideoElement
This is fairly standard, here we’ll load an H.264 MP4 with the filename “test.mp4”:
Next, we want to seek to a point in the video where we want to capture the frame and also bind to an event that’ll tell us when we’re able to read the frame data from the HTMLVideoElement. The seeked event works well. The other potentially viable option is the loadeddata event, but I ran into some issues here, which I’ll describe later.
video.addEventListener('seeked', function(e) {
// capture the video frame at the point seeked to...
});
// seek to 2s
video.currentTime = 2;
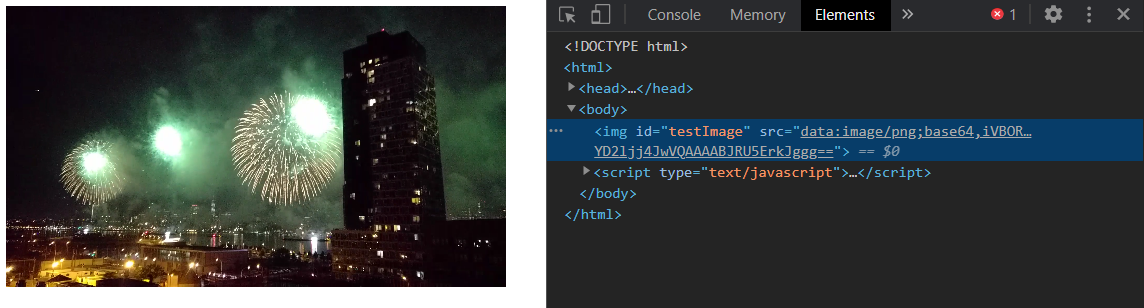
I added this method to the canvas-image-transformer library; referencing the method we can now flesh out the seeked event handler. For this test, we’ll also render out what’s on the canvas to an <img> element in the document to see what’s been captured.
video.addEventListener('seeked', function(e) {
// capture the video frame at the point seeked toconst frameOnCanvas = CanvasImageTransformer.videoFrameToCanvas(video, 500, 500, true);
document.getElementById('testImage').src = frameOnCanvas.toDataURL();
});
frameOnCanvas is a canvas with the captured frame, and here’s what it looks like transformed & rendered into an <img> element:
Issues
Something not immediately obvious is that the seeked event is not fired if video.currentTime = 0 (i.e. you want to seek to the first frame of a video). However, you can use a very small time value (e.g. video.currentTime = 0.000000001), which will typically seek to the first frame in most cases. That said, it is a hacky/non-elegant solution.
There are cross-browser issues with the loadeddata event. In Firefox, you will only get a frame capture if you don’t seek. If you do attempt to seek, you’ll get a empty frame and the canvas will have a transparent image. Conversely, in Chrome (and other Webkit-based browsers), you will only get a frame if you do seek. The standard states that the event should be fired when “the user agent can render the media data at the current playback position for the first time” which seem to indicate an implementation flaw in both browsers.
The test video was taken on my phone and the frames themselves are upsided-down, this is typical with smartphone videos as it’s expected that playback will take into account metadata indicating orientation. In Firefox, this isn’t taken into account when using CanvasRenderingContext2D.drawImage() with HTMLVideoElement, so you get an upsided-down image on the canvas.
Alternatives & limitations
I couldn’t think of a ton of options for decoding H.264 or VP8/VP9. If you’re looking to create something yourself, a server-side service invoking FFmpeg seems like the best option. I played around with Puppeteer, but Puppeteer comes with Chromium, which lacks the audio and video support you get out-of-the box with Chrome. Although, installing and using Chrome server-side with Puppeteer has potential.
There are also third-party services which can handle video decoding and transcoding, and those are solid server-side options.
As with thumbnail generation, here again we’re looking at workloads that have potential to be moved to the frontend, where you have hardware better suited for graphics work and the possibility of reducing backend complexity. On the other hand, the same limitations comes into play, as you have less control over the execution environment and no clear path for backfill or migration needs.
As the APIs brought forward by HTML5 about a decade ago have matured and the devices running web browsers have continued to improve in computational power, looking at what’s possible on the frontend and the ability to bring backend computations to the frontend has been increasingly interesting to me. Such architectures would see each user’s browsers as a worker for certain tasks and could simply backend systems, as those tasks are pushed forward to the client. Using Canvas for image processing tasks is one area that interesting and that I’ve had success with.
For Mural, I did the following Medium-esque image preload effect, the basis of which is generating a tiny (16×16) thumbnail which is loaded with the page. That thumbnail is blurred via CSS filter, and transitions to the full-resolution image once it’s loaded. The thumbnail itself is generated entirely on the frontend when a card is created and saved alongside the card data.
In this post, I’ll run though generating and handling that 16×16 thumbnail. This is fairly straightforward use of the Canvas API, but it does highlight how frontend clients can be utilized for operations typically relegated to server-side systems.
A precursor for any sort of image processing is getting the image data into a <canvas>. The <img> element and corresponding HTMLImageElement interface don’t provide any sort of pixel-level read/write functionality, whereas the <canvas> element and corresponding HTMLCanvasElement interface does. This transformation is pretty straightforward:
Use the Image constructor to load an image or reference an <img> element from the DOM
Create a canvas with the same width and height as the image
The code is as follows (an interesting thing to note here is that this can all be done without injecting anything into the DOM or rendering anything onto the screen):
const img = new Image();
img.onload = function() {
const canvas = document.createElement('canvas');
canvas.width = img.width;
canvas.height = img.height;
const canvasCtx = canvas.getContext('2d');
canvasCtx.drawImage(img, 0, 0, img.width, img.width);
// the image has now been rendered onto canvas
}
img.src = "https://some-image-url";
Resizing an image
Resizing is trivial, as it can be handled directly via arguments to CanvasRenderingContext2D.drawImage(). Adding in a bit of math to do proportional scaling (i.e. preserve aspect ratio), we can wrap the transformation logic into the following method:
My goto method for getting the data off a canvas and into a more interoperable form is to use the HTMLCanvasElement.toDataURL() method, which allows easily getting the image as a PNG or JPEG. I do have mixed feeling about data-URIs; they’re great for the web, because so much of the web is textually based, but they’re also horribly bloated and inefficient. In any case, I think interoperability and ease-of-use usually wins out (esp. here where we’re dealing with a 16×16 thumbnail and the data-uri is relatively lightweight) and getting a data-uri is generally the best solution.
Using CanvasRenderingContext2D.getImageData() to get the raw pixel from a canvas is also an option but, for a lot of use-cases, you’d likely need to compress and/or package the data in some way to make use of it.
Save the transformed image
With a data-uri, saving the image is pretty straightforward. Send it to the server via some HTTP method (POST, PUT, etc.) and save it. For a 16×16 PNG the data-uri textual representation is small enough that we can put it directly in a relational database and not worry about a conversion to binary.
Alternatives & limitations
The status quo alternative is having this sort of image manipulation logic encapsulated within some backend component (method, microservice, etc.) and, to be fair, such systems work well. There’s also some very concrete benefits:
You are aware of and have control over the environment in which the image processing is done, so you’re isolated from browser quirks or issues stemming from a user’s computing environment.
You have an easier path for any sort of backfill (e.g. how do you generate thumbnails for images previously uploaded?) or migration needs (e.g. how can you move to a different sized thumbnail?); you can’t just run though rows in a database and make a call to get what you need.
However, something worth looking at is that backend systems and server-side environments are typically not optimized for any sort of graphics workload, as processing is centered around CPU cores. In contrast, the majority of frontend environments have access to a GPU, even fairly cheap phone have some sort of GPU that is better suited for “embarassing parallel”-esque graphics operations, the performance benefits of which you get for free with the Canvas API in all modern browsers.
In Chrome, see the output of chrome://gpu:
Scale, complexity and cost also come into play. Thinking of frontend clients as computational nodes can change the architecture of systems. The need for server-side resources (hardware, VMs, containers, etc.) is eliminated. Scaling concerns are also, to a large extent, eliminated or radically changed as operations are pushed forward to the client.
Future work
What’s presented here is just scratching the surface of what’s possible with Canvas. WebGL also presents as a ton of possibilities and abstraction layers like gpu.js are really interesting. Overall, it’s exciting to see the web frontend evolve beyond a mechanism for user input and into a layer in which substantive computation can be done.
In my previous post on ES modules, I mentioned adopting the mjs file extension for modules files. Unfortunately, there’s no entry for the mjs extension in nginx’s default mime.types file, meaning it’ll be served as application/octet-stream instead of application/javascript. The MIME type for mjs files can be set by explicitly including mime.types in a server, http, or location block & adding a types block with the MIME type and file extension:
server
{
include mime.types;
types
{
application/javascript mjs;
}
...
}
ES modules are one of the more exciting additions to the Javascript language. Effectively being able to break-off and modularize has continually led to better code and development practices in my experience. For server-side Javascript, Node and its associated module system took hold, but there was nothing comparable for browsers. However, Node-based toolchains to produce frontend code also became a thing, doing rollup, transpilation, minification, etc. This wasn’t necessarily a bad thing, and came with some noted benefits such as better support for unit testing scaffolds and integration into CI pipelines, but it also set a stage for increasingly complex toolchains and an ecosystem whereby frontend components were Node-based server-side components first, and transformed into frontend components after. The latter, in turn, led to a state where you were always working with a toolchain (it wasn’t just for CI or producing optimized distributables) as there was no path to directly load these components in a browser, and I’d argue also led to a state where components were being composed with an increasing and ridiculous number of dependencies, as the burden of resolving and flattening dependencies fell to to the toolchain.
ES modules aren’t any sort of silver bullet here, but it does show a future where some of this complexity can be rolled back, the toolchain only needs to handle and be invoked for specific cases, and there is less impedance in working with frontend code. We’re not there yet, but I’m hopeful and as such I’ve adopted ES modules in projects where I’ve been able to.
A look at GraphPaper
GraphPaper was the first project where I committed to ES modules for the codebase. At the time, support for ES modules was limited in both Node and browsers (typically incomplete support and put behind a feature flag), so for both development work and producing distributables, I used rollup.js + Babel to produce an IIFE module. This worked well, though it’s a pain to do a build every for every code change I want to see in the browser. I also remember this being pretty easy to setup initially, but the package.json became more convoluted with Babel 6, when everything was split into smaller packages (I understand the rationale, but the developer experience is horrible and pushes the burden of understanding various babel components to consumers).
Structuring the module
Structuring was fairly simple. Everything that was meant to be accessible by consumers was declared in a single file (GraphPaper.js), declared via export statements (i.e. it was just a file with a bunch of export * from … statements). This file also served as the input for rollup.js:
In a modern browser, it would be possible to import the GraphPaper ES module directly, like so:
<script type="module">
import * as GraphPaper from'../src/GraphPaper.js';
...
</script>
However, the way dependent web workers are built and encapsulated makes this impossible (explained here).
Another problem, but one that’s fixable, is that I wrote import and export statements without file extensions. For browsers, this leads to an issue as the browser will just request what’s declared in the statement and not append any file extension (so a statement like import { LineSet } from'./LineSet'; results in a request to the server for ./LineSet, not ./LineSet.js, as the file is named. Moving forward, the recommendation to use the .mjs extension and explicitly specifying the extension in import statements seems to be a good idea; in addition to addressing the issue with browser requests, when working in Node .mjs files will automatically be treated as ES modules.
Pushing aside the web worker issue, we can see a future where rollup.js isn’t necessary, or at least not necessary for producing browser-compatible (e.g. IIFE) modules. It’s role can be limited to concatenation and orchestrating optimizations (e.g. minification) for distributables. Similarly, for Babel, it’s role can be reduced or eliminated. As support for newer ES features (particularly those in ES6 and ES7) continues to improve across systems (browsers, Node, etc.), and users adopt these systems, transpilation won’t be as necessary. The exception is the case where developers want to use the very latest ES features, but I think we’re quickly approaching a point of diminishing returns here, especially relative to the cost of toolchain complexity.
Testing with jasmine-es6, moving to Ava
For testing, I found jasmine-es6 to be one of the simpler ways to test ES modules at the time. Ava existed, but I remember running into issues getting it working. I remember also toying with Jest at some point and also running into issues. In the end, jasmine-es6 worked well, I never had issues importing and writing tests for a module. Here’s a sample test from the codebase:
import { Point } from'../src/Point'import { Line } from'../src/Line'import { LineSet } from'../src/LineSet'
describe("LineSet constructor", function() {
it("creates LineSet from Float64Array coordinates", function() {
const typedArray = Float64Array.from([1,2,3,4,5,6,7,8]);
const ls = new LineSet(typedArray);
const lineSetArray = ls.toArray();
expect(ls.count()).toBe(2);
expect(lineSetArray[0].isEqual(new Line(new Point(1, 2), new Point(3, 4)))).toBe(true);
expect(lineSetArray[1].isEqual(new Line(new Point(5, 6), new Point(7, 8)))).toBe(true);
});
});
jasmine-es6 has and continues to work really well despite being deprecated. I’ll likely adopt and reformat the tests to Ava at some point the future. I’ve played around with it again recently and it was a much smoother experience, it’s also better supported and I like the simpler syntax around tests more-so than the Jasmine syntax. I’m looking to do this when Node has stable support for ES modules, as this would mean not worrying about pulling in and configuring Babel for running tests (though it’ll likely still be around for rollup.js).
Takeaways
Overall, it’s been fairly smooth working with ES modules and it looks like things will only improve in the future. Equally exciting is the potential reduction in toolchain complexity that comes with better support for ES modules.
Support for ES modules continues to improve across libraries, browsers, and Node
It’s probably a good idea to use the .mjs file extension
Rollup.js is still needed for now to make browser-compatible (e.g. IIFE) modules, but will likely take on a more limited role in the future (concatenation & minification)
Better support for ES6 and ES7 features across the board will mean that Babel, and transpilation in general, won’t be as necessary
Due to browser restrictions, you typically can’t have a setInterval call where the delay is set to 0, from MDN:
In modern browsers, setTimeout()/setInterval() calls are throttled to a minimum of once every 4 ms when successive calls are triggered due to callback nesting (where the nesting level is at least a certain depth), or after certain number of successive intervals.
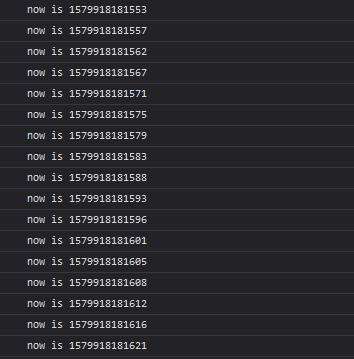
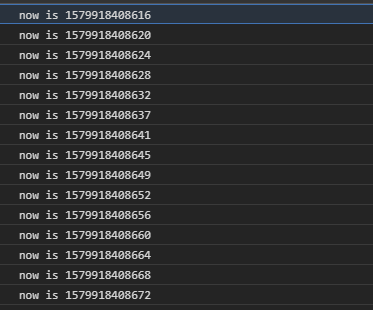
I confirmed this by testing with the following code in Chrome and Firefox windows:
setInterval(() => {
console.log(`now is ${Date.now()}`);
}, 0);
In Firefox 72:
In Chrome 79:
The delay isn’t exact, but you can see that it typically comes out to around 4ms, as expected. However, things are a little different with web workers.
The delay with web workers
To see the timing behavior within a web worker, I used the following code for the worker:
… and created it via const worker = new Worker('worker.js');.
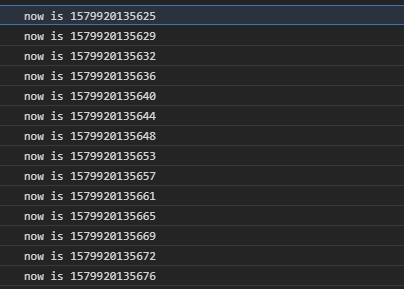
In Chrome, there’s no surprises, the behavior in the worker was similar to what it was in the window:
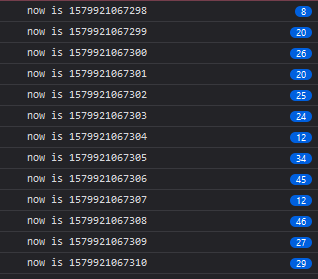
Things get interesting in Firefox:
Firefox starts grouping the log messages (the blue bubbles), as we get multiple calls to the function within the same millisecond. Firefox’s UI becomes unresponsive (which is weird and I didn’t expect as this is on an i7-4790K with 8 logical processors and there’s little interaction between the worker and the parent window), and there’s a very noticeable spike in CPU usage.
Takeaway
setInterval() needs a delay and you shouldn’t depend on the browser to set something reasonable. It would be nice if setInterval(.., 0) would tell the browser to execute as fast as reasonably possible, adjusting for UI responsiveness, power consumption, etc. but that’s clearly not happening here and as such it’s dangerous to have a call like this which may render the user’s browser unresponsive.
Web workers handle incoming request messages via a function declared on the onmessage property of the worker. A, perhaps not so obvious, behavior here is that incoming requests are queued. If you’re doing something intensive within the worker (or the CPU is taxed b/c of other processes) the queuing behavior becomes more obvious, as you need to wait longer for a response from the worker due to the fact that previous requests need to be picked up and handled first. Here’s a simple worker that does some heavy lifting (at least for Chrome 79 on an i7-4790K):
… and here’s what happens after making 12 requests to it in a loop:
I can’t say that this is a bad thing, this is generally sensible and what you’d expect to happen. That said, there are workloads where you may want to prioritize things differently. GraphPaper was one such case for me. Workers are handling things based on user interactions, the last request represents the current state of the world and is typically the only request that matters (any others from before can be thrown away). Unfortunately, this is no mechanism to interact with or re-prioritize messages in this underlying queue. However, you can offload the requests to a queue that the worker manages internally by itself. The onmessage() function simply puts the request data in a queue and we can use setInterval() to continuously call a function that pulls and processes requests from this queue. Here’s what the modified worker code looks like, where the latest request is prioritized (and previous ones are thrown away):
… and here’s what happens after making 12 requests to it in a loop:
(sometimes, there are also cases where only request 12 was processed)
So this works pretty well, but there there are a few things to be aware of. The time it takes to post a message to the worker, is somewhere between 0ms – 1ms, plus the cost of copying any data that needs to be transferred to the worker. The setInterval() minimum is not really 0ms; the browser sets a reasonable minimum which you can probably expect to be between 4ms – 10ms, and this is in addition to the cost of posting the message to the worker (The code was updated to explicitly specify a 4ms delay, setInterval with a 0ms delay isn’t a good idea). What this means in practice is that there is additional latency before we begin processing a request, but compared to a scenario where we have to factor in waiting on all prior requests to finish processing (which is the point of doing this to begin with), I expect this method to win out in performance.
Finally, here’s a look at a GraphPaper stress test and how prioritizing the last request to the connector routing worker (which is responsible for generating the path between the 2 nodes) allows for a faster/less-laggy update:
There’s generally 2 ways to construct a Web Worker…
Passing a URL to the Javascript file:
const myWorker = new Worker('worker.js');
Or, creating a URL with the Javascript code (as a string). This is done by creating a Blob from the string and passing the Blob to URL.createObjectURL:
const myWorker = new Worker(
URL.createObjectURL(new Blob([...], {type: 'application/javascript'}))
);
In Practice
With GraphPaper, I’ve used the former approach for the longest while, depending on the caller to construct and inject the worker into GraphPaper.Canvas:
const canvas = new GraphPaper.Canvas(
document.getElementById('paper'), // div to usewindow, // parent window new Worker('../dist/connector-routing-worker.min.js') // required worker for connector routing
);
This technically works but, in practice, there’s 2 issues here:
There’s usually a few hoops to go through for the caller to actually get the worker Javascript file in a location that is accessible by the web server. This could mean manually moving the file, additional configuration, additional tooling, etc.
GraphPaper.Canvas is responsible for dealing with whether a worker is used or not, which worker, how many workers are used, etc. These aren’t concerns that should bubble up to the caller. You could make a case that caller should have the flexibility to swap in a worker of their choice (a strategy pattern), that’s a fair point, but I’d argue that the strategy here is what the worker is executing not the worker itself and I haven’t figured out a good interface for what that looks like.
So, I worked to figure out how to construct the worker within GraphPaper.Canvas using URL.createObjectURL(), and this is where things got trickier. The GraphPaper codebase is ES6 and uses ES6 modules, I use rollup with babel to produce distribution files the primary ones being minified IIFE bundles (IIFE because browser support for ES6 modules is still very much lacking). One of these bundles is the code for the worker (dist/connector-routing-worker.js), which I’d need to:
Encapsulate it into a string that can be referenced within the source
Create a Blob from the string
Create a URL from the Blob using URL.createObjectURL()
Pass the URL to the Worker constructor, new Worker(url)
The latter steps are straightforward function calls, but the first is not clear cut.
Repackaging with Rollup
After producing the “distribution” code for the worker, what I needed was to encapsulate it into a string like this (the “worker-string-wrap”):
Writing that out to a file, I could then easily import it as just another ES6 module (and use the string to create a URL for the worker), then build and produce the distribution file for GraphPaper.
I first tried doing this with a nodejs script, but creating a rollup plugin proved a more elegant solution. Rollup plugins are aren’t too difficult to create but I did find the documentation a bit convoluted. Simply, rollup will execute certain functions (hooks) at appropriate points during the build process. The hook needed in this scenario is writeBundle, which can be used to get the code of the produced bundle and do something with it (in this case, write it out to a file).
Note that addtional config blocks for components that use ConnectorRoutingWorker.string.js (e.g. the GraphPaper distribution files), need to be placed after the block shown above.
The overall process looks like this:
Creating the Worker
The worker can now be created within the codebase as follows:
Looking ahead, I don’t really see a good solution here. Better support for ES6 modules in the browser would be a step in the right direction, but what is really needed is a way to declare a web worker as a module and the ability to import and construct a Worker with that module.