Improving on strip_tags
Avishkar Autar · Aug 13 2022 · PHP
The Problem
PHP’s strip_tags() method will strip away tags but makes no attempt to introduce whitespace to separate content in adjacent tags. This is an issue with arbitrary HTML as adjacent block-level elements may not have any intermediate whitespace and simply stripping away the tags will incorrectly concatenate the textual content in the 2 elements.
For example, running strip_tags() on the following:
<div>the quick brown fox</div><div>jumped over the moon</div>
… will return:
the quick brown foxjumped over the moon
This is technically correct (we’re stripped away the <div> tags) but having no whitespace between “fox” and “jumped” means we’ve transformed the content such that we’ve lost semantic and presentational details.
The Solution
There’s 2 ways I can see to fix this behavior:
- Pre-process the HTML content to ensure or introduce whitespace between block-level elements
- Don’t use
strip_tags()and utilize a method that better understands the need for spacing between elements
I’ll focus on the latter because that’s the avenue I went down and I didn’t consider pre-processing at the time.
Pulling together a quick-and-dirty parser, I wrote the following. It’s worth noting that still still doesn’t really consider what the tags are (e.g. whether they’re inline or block) but allows the caller to specify a string ($tagContentSeparator), typically some whitespace, that is inserted between the stripped away tags:
<?php
class HTMLToPlainText
{
const STATE_READING_CONTENT = 1;
const STATE_READING_TAG_NAME = 2;
static public function convert(string $input, string $tagContentSeparator = " "): string
{
// the input string as UTF-32
$fixedWidthString = iconv('UTF-8', 'UTF-32', $input);
// string within tags that we've found
$foundContentStrings = [];
// buffer for current content being read
$currentContentString = "";
// flag to indicate how we should interpret what we're reading from $fixedWidthString
// .. this is initially set to STATE_READING_CONTENT, as we assume we're reading content from the start, even
// if we haven't encountered a tag (e.g. string that doesn't contain tags)
$parserState = self::STATE_READING_CONTENT;
// method to add a non-empty string to $foundContentStrings and reset $currentContentString
$commitCurrentContentString = function() use (&$currentContentString, &$foundContentStrings) {
if(strlen($currentContentString) > 0) {
$foundContentStrings[] = trim($currentContentString);
$currentContentString = "";
}
};
// iterate through characters in $fixedWidthString
// checking for tokens indicating if we're within a tag or within content
for($i=0; $i<strlen($fixedWidthString); $i+=4) {
// convert back to UTF-8 to simplify character/token checking
$ch = iconv('UTF-32', 'UTF-8', substr($fixedWidthString, $i, 4));
if($ch === '<') {
$parserState = self::STATE_READING_TAG_NAME;
$commitCurrentContentString();
continue;
}
if($ch === '>') {
$parserState = self::STATE_READING_CONTENT;
continue;
}
if($parserState === self::STATE_READING_CONTENT) {
$currentContentString .= $ch;
continue;
}
}
$commitCurrentContentString();
return implode($tagContentSeparator, $foundContentStrings);
}
}
Note that the to/from UTF-8 ↔ UTF-32 isn’t really necessary, I initially did the conversion as I was worried about splitting a multibyte character, but this isn’t possible given how the function reads the input string.
Now if we take the following HTML snippet:
<div>the quick brown fox</div><div>jumped over the moon</div>
… rendered in a browser, we get:
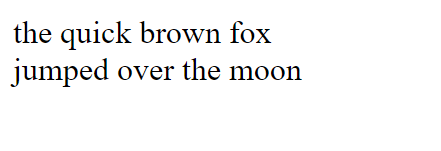
… with strip_tags() we get:
the quick brown foxjumped over the moon
… and with HTMLToPlainText::convert() (passing in “\n” for $tagContentSeparator), we get:
the quick brown fox
jumped over the moon
The latter results in text that is semantically correct, as words in different blocks aren’t incorrectly joined. Presentationally we also get a more correct conversion but, the method isn’t really doing anything fancy here, this is due to the calling knowing a bit about the HTML snippet, how a browser would render it, and passing passing in “\n” for $tagContentSeparator.
Limitations / future work
The improvement here is that textual content is pretty preserved when doing a conversion, i.e. we don’t have to worry about textual elements being incorrectly concatenated. However, what I wrote is still lacking in 2 keys areas:
- Generally, in terms of presentation, an arbitrary bit of HTML won’t map to what a user sees in a browser. To a certain degree this is an intractable problem, as presentation is based on browser defaults, CSS styles, etc. Also, there are things that simply don’t have a standard representation in plain-text (e.g. bold text, list items, etc.). However, there are cases where sensible defaults might make sense, e.g. stripping away
<span>tags but putting newline between<p>tags. - Whitespace is trimmed from content within tags. This may or may not matter depending on application. In my case, I cared about the words and additional whitespace just added bloat even if it was more accurate to what was in the HTML.
EDIT: See part 2 on addressing these limitations and making the code more robust.







