Versioning datasets
Avishkar Autar · Dec 5 2022 · Software Engineering
Contracts
An issue I’ve kept coming across when working on data systems that involve producing and consuming a number of different datasets is the lack of a contract between producers and consumers. Versioning provides a solution to this problem when dealing with software and, with a decent versioning scheme, provides a good solution for datasets as well, allowing for the creation of versioned snapshots.
Data concerns
It’s worth looking at what the problem is here and why this even matters. Imagine having some dataset, let’s say for drugs, which is periodically updated. We could reasonably say that we only care about the latest version of the drugs dataset, so every time we ingest new data, we simply overwrite the existing dataset.
For a rudimentary system, this is fine, but if we’re thinking in terms of a larger data system with this dataset being consumed by downstream processes, teams, and/or customers, there are a few concerns our system can’t elegantly deal with:
- Corruption: the ingested data is corrupt or a bug in the ETL process results in a corrupted dataset
- Consistent reads: not all parts (e.g. tables) of our dataset may be ready for reads by consumers at a given time (loading data to S3 is a good example here; for a non-trivial dataset with multiple objects and partitions, spread across multiple objects, the dataset as a whole can’t be written/updated atomically)
- Breaking changes: a breaking change to downstream systems (e.g. dropping a column) may need to be rolled out
- Reproducibility: downstream/derived datasets may need to be re-created based upon what the dataset was at some point in the past (i.e. using the latest dataset will not give the same results)
- Traceability: we may need to validate/understand how a derived data element was generated, requiring an accurate snapshot of all input data when the derived dataset was generated
Versioning isn’t the only solution to these concerns. You could argue that frequent backups, some sort of locking mechanism, coordination between teams, and/or very granular levels of observability can address each to varying degrees, but I think versioning is (a) simple and (b) requires the least effort.
Versioning scheme
Let’s look at a versioning scheme that would address the 4 concerns I raised above. For this, I’m going to borrow from both semantic versioning and calendar versioning. Combining the 2, and adding a bit of additional metadata, we can construct a scheme like the following:
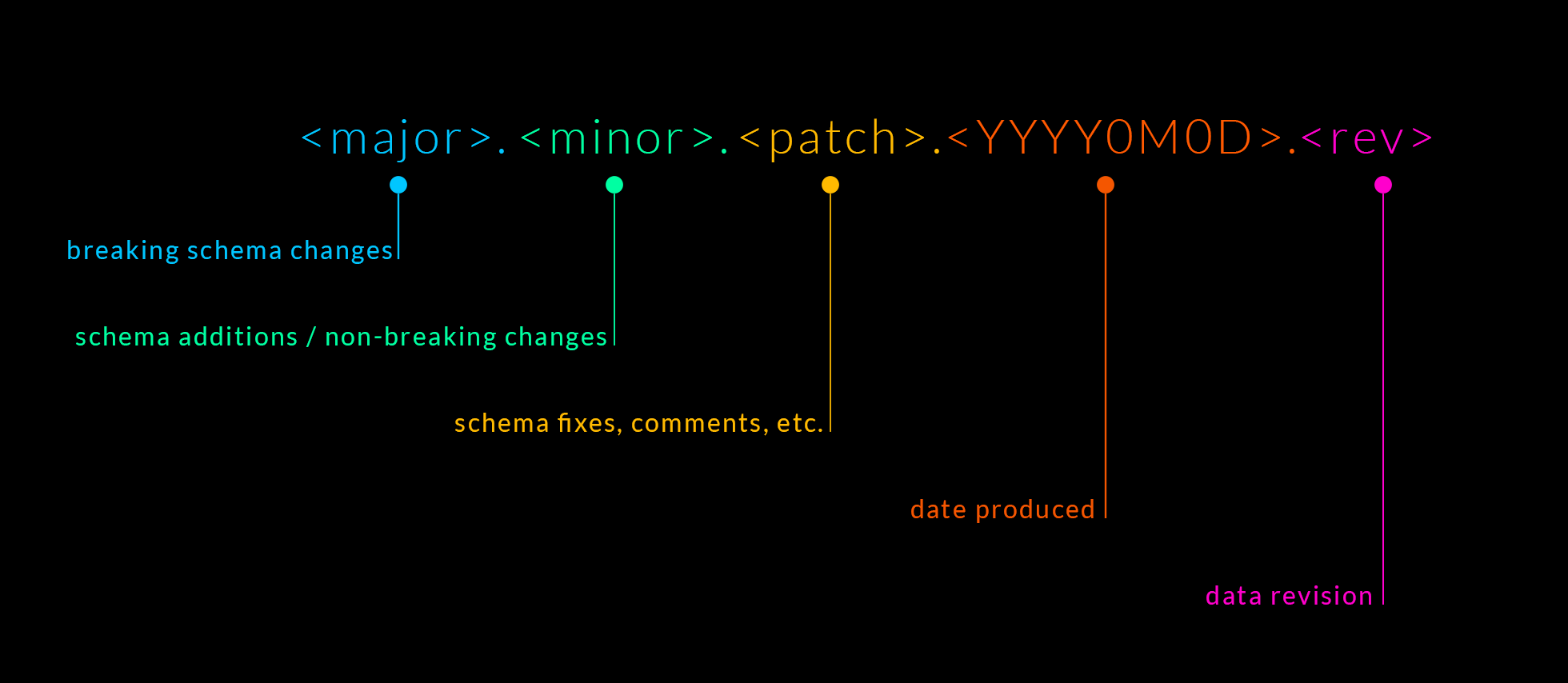
Breaking this down:
- The semantic versioning components (major, minor, patch) can effectively tell us about the spatial nature of the dataset; the schema.
- The calendar versioning components (
YYYY0M0D) can effectively tell us about the temporal nature of the dataset (when it was ingested, generated, etc.). Note that calendar versioning is a lot more fuzzy as a standard, as there’s a lot of variance in how dates are represented,YYYY0M0Dseems like a good choice as it’s easily parsable by consumers. - The final component (rev) is the revision number for the given date and is needed for datasets that can be generated/refreshed multiple times in a day. I think of this as an incrementing integer but a time component (hours, minutes, seconds) is another option; either can work, there’s just tradeoffs in implementation and consumer expectations.
Finding a version
Going back to our example, our data flow now looks something like this:
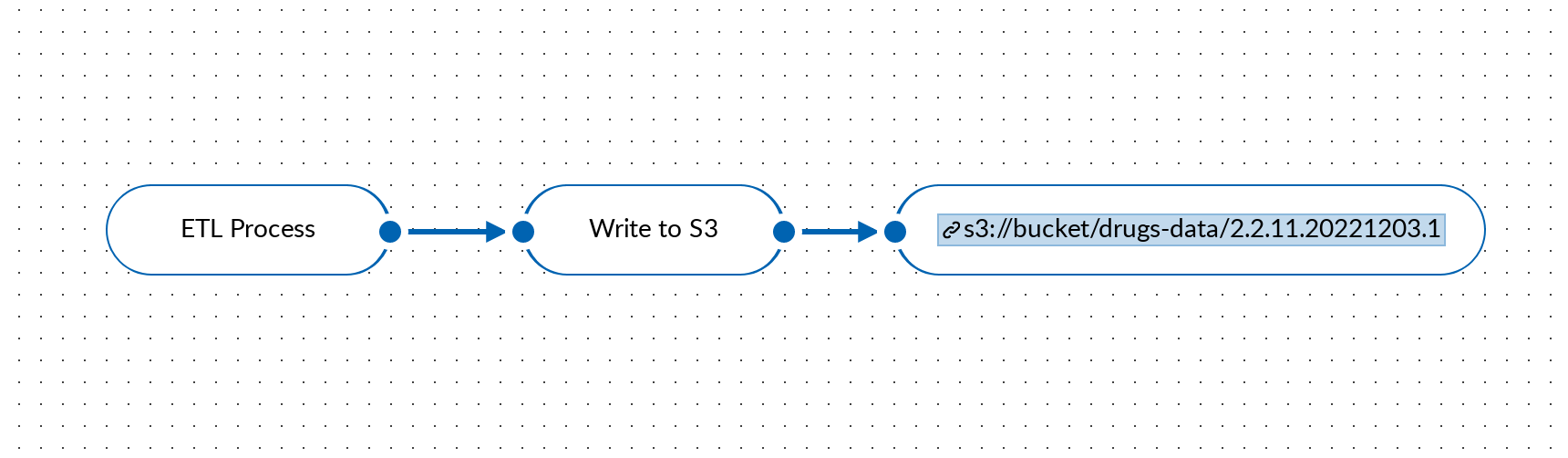
Note that before our consumers knew exactly where to look for the dataset (s3://bucket/drugs-data/latest), more specifically the latest version of the dataset, however, this is no longer the case. Consumers will need to figure out what version of the dataset they want. This could be trivial (e.g. consumers just want to pin to a specific version) but the more interesting and perhaps more common case, especially with automated systems, is getting the latest version. Unpacking “latest” is important here: consumers want the latest data but not if it carries with it a breaking schema change (i.e. consumers want to pin to major version component, with the others being flexible). Thinking in terms of npm-esque ranges with the caret operator, a consumer could specify a version like ^2.2.11.20221203.1 indicating they system is able to handle, and should pull in, any newer, non-breaking, updates in either schema or data.
So consumers can indicate what they want, but how does a system actually go about finding a certain version? I think the elegant solution here is having some sort of metadata for the dataset that can tell consumers what versions of the dataset are available and where to find them. Creating or updating these metadata entries can simply be another artifact of the ETL process and can be store alongside the dataset (in a manifest file, a table, etc.). Unfortunately, this does involve a small lift and a bit of additional complexity for consumers, as they’d have to read/parse the metadata record.
Dataset-level vs. Data-level versioning
In researching other ways in which versioning is done, change data capture methods usually come up. While change data capture methods are important and powerful, CDC methods are typically at the row-level, not the dataset-level, and it’s worth recognizing the distinction, especially from data systems perspective, as CDC methods come with very different architectural and implementation concerns.
For example, in this blog post from lakeFS, approach #1 references full duplication, which is dataset versioning, but then approach #2 references valid_from and valid_to fields, which is a CDC method and carries with it the requirement to write queries that respect those fields.
Avoiding full duplication
The scheme I’ve laid out somewhat implies a duplication of records for every version of a dataset. I’ve seen a number of articles bring this up as a concern, which can very well be true in a number of case, but I’m skeptical of this being a priority concern for most businesses, given the low cost of storage. In any case, I think storage-layer concerns may impact how you reference versions (more generally, how you read/write metadata), but shouldn’t necessarily dictate the versioning scheme.
From what I’ve read, most systems that try to optimize for storage do so via a git-style model. This is what’s done by cloud service providers like lakeFS and tools like git LFS, ArtiV, and DVC.
Alternatives
I haven’t come across much in terms of alternatives but, in addition to a semantic identifier, this DZone article also mentions data versions potentially containing information about the status of the data (e.g. “incomplete”) or information about what’s changed (e.g. “normalized”). These are interesting ideas but not really something I’ve seen a need for in the version identifier. That said, what I’ve presented is not intended to be some sort of silver bullet, I’m sure different engineers face different concerns and different versioning schemes would be more appropriate.
In the end, I would simply encourage engineers to consider some form of versioning around their datasets, especially in larger data systems. It’s a relatively simple tool that can elegantly address a number of important concerns.







