Numbering items within groups in MySQL
Sep 20 2013 · SQL
In my previous post, I described computing row numbers for items within a result set. If items in the result set can be ordered into groups, you can use the same technique to number items within the groups. This is valuable as it allows you to get the top 3, top 5, top N … items within each group (note that GROUP BY isn’t appropriate here; we don’t want to aggregate items within a group, we want an ordering of all the items within a group).
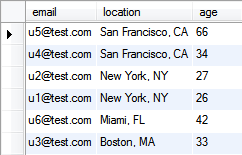
Consider the following sample of data where we’ve done an ordering by the location and age fields (ORDER BY location DESC, age DESC). Every user’s email address is within a group (location) and within that group users are sorted by age in descending order.
SELECT mytable.*
FROM mytable
ORDER BY location DESC, age DESC
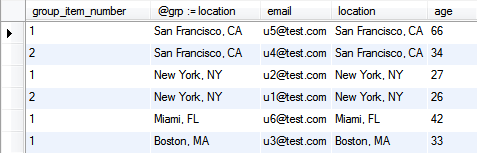
By using two variables, one to keep track of the item number (@itm) and another to keep track of the current group (@grp), and incrementing the item number if the current group has not changed, else resetting it to 1, we get a numbering of each item within each group. In this example, the group item number tells us who is the 1st oldest, 2nd oldest, etc. user in each location.
SELECT
@itm := IF(@grp = location, @itm + 1, 1) AS group_item_number,
@grp := location,
mytable.*
FROM mytable,
(SELECT @itm := 0) AS itm_num_init,
(SELECT @grp := NULL) AS grp_init
ORDER BY location DESC, age DESC