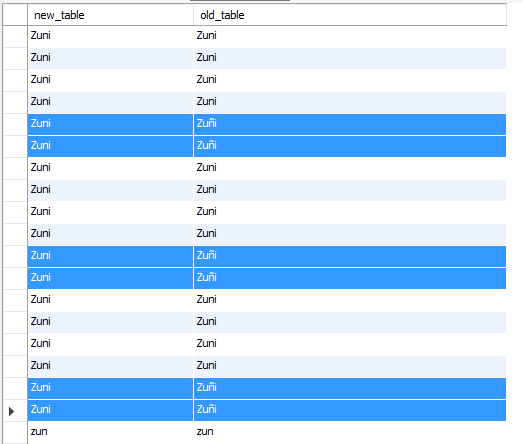
One of the more interesting things I’ve learned about recently, that’s proven itself incredibly useful, is the pivot table. A pivot table turns rows into columns. This may seem odd, but the utility of this transformation becomes apparent when you have data that can’t be modeled precisely by a set of attributes because there are attributes which apply to some pieces of data and not others. The typical solution to this problem is simply to have additional columns, allowing for NULL values or defining an appropriate default value (e.g. empty string). However, with a large number of attributes or with user-defined attributes, this solution becomes unattractive, and constructing a pivot table is preferable.
Here I’ll present an example of constructing a pivot table for a schema in which a number of optional attributes, stored as key-value pairs, are attributed to entities. Here’s an ER diagram of the simple schema used in this example:
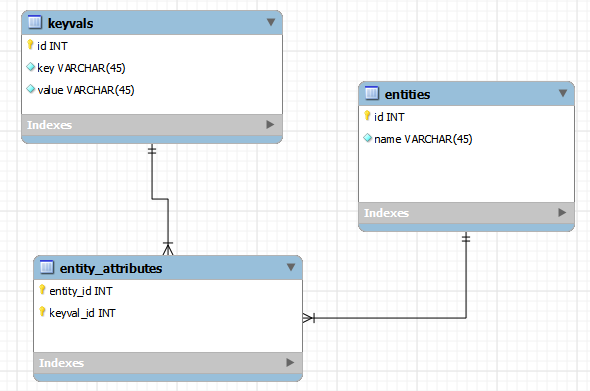
- entities holds a list of entities (companies, users, etc.), with name being the only attribute required for all entities.
- keyvals hold a list of key-value pairs to associate with entities.
- entity_attributes maps keyvals to entities.
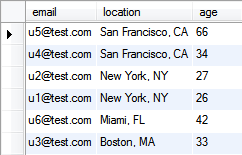
An SQL query to grab all entities and all associated keyvals would look something like this:
SELECT *
FROM entities
LEFT JOIN entity_attributes ea ON ea.entity_id=entities.id
LEFT JOIN keyvals kv ON kv.id = ea.keyval_id
WHERE 1;
… this would return every entity LEFT JOINed with any associated keyval:
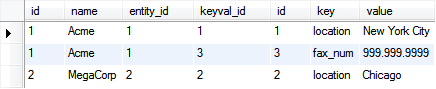
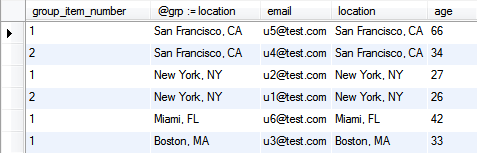
We can turn each entry in the key column (keyvals.key) into its own column, with rows having the corresponding entry from the value column (keyvals.value), using a simple conditional statement and alias as shown below:
SELECT entities.*,
IF(kv.key='location', kv.value, '') AS location,
IF(kv.key='fax_num', kv.value, '') AS fax_num
FROM entities
LEFT JOIN entity_attributes ea ON ea.entity_id=entities.id
LEFT JOIN keyvals kv ON kv.id = ea.keyval_id
WHERE 1;
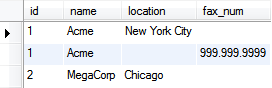
The keys, location and fax_num, are now represented as columns. For entities with 2+ associated keyvals, we still have multiple rows for each entity, but the data is such that each row only holds a single value entry (keyvals.value) for a single key (keyvals.key), under the respective column. To get a single row per entity, we GROUP BY the entity and take the MAX of each key column.
SELECT entities.*,
MAX(IF(kv.key='location', kv.value, '')) AS location,
MAX(IF(kv.key='fax_num', kv.value, '')) AS fax_num
FROM entities
LEFT JOIN entity_attributes ea ON ea.entity_id=entities.id
LEFT JOIN keyvals kv ON kv.id = ea.keyval_id
WHERE 1
GROUP BY entities.id;
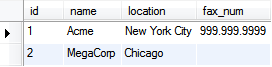
The result is a pivot table.