Pushing computation to the front: client-side compression
Dec 25 2020 · Web Technologies
Client → Server Compression
Content from a web server being automatically gzipped (via apache, nginx, etc.) and transferred to the browser isn’t anything new, but there’s really nothing in the way of compression when going in the other direction (i.e. transferring content from the client to the server). This is not too surprising, as most client payloads are small bits of textual content and/or binary content that is already well compressed (e.g. JPEG images), where there’s little gain from compression and you’re likely to just waste CPU cycles doing it. That said, when your frontend client is a space for content creation, you’re potentially going to run into cases where you’re sending a lot of uncompressed data to the server.
Use-case: ScratchGraph Export
ScratchGraph has an export feature that essentially renders the page (minus UI components) as a string of HTML. This string packaged along with some metadata and sent to the server, which sends it to a service running puppeteer, that renders the HTML string to either an image or a PDF. The overall process looks something like this:
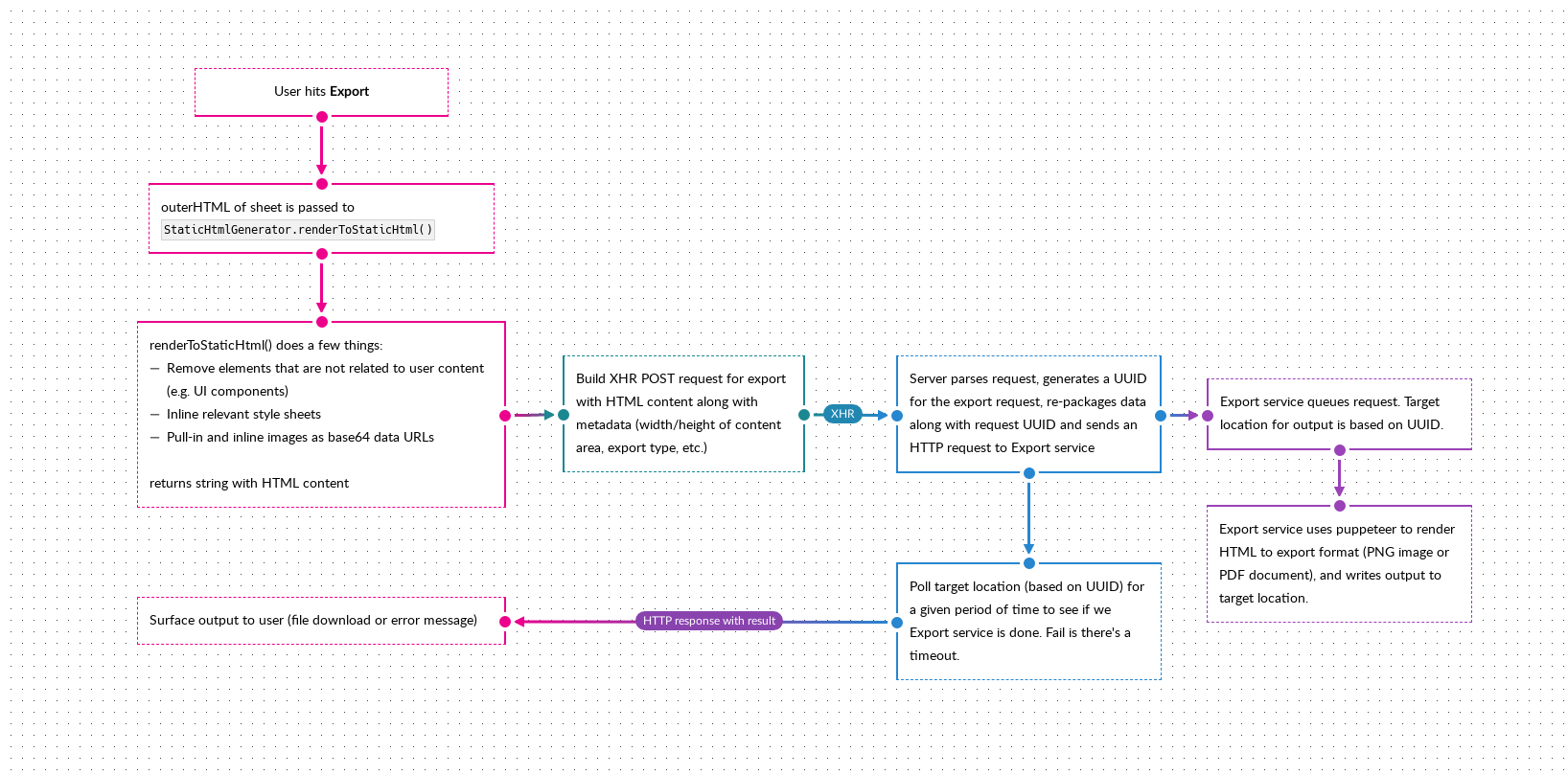
The HTML string being sent to the server is relatively large, a couple of MBs, due to:
- The CSS styles (particularly due to external resources being pulled in and inlined as base64 URLs)
- The user simply having lots of content
To be fair, it’s usually the former rather than the latter, and optimizing to avoid the inlining of resources (the intent of which was to try and do exports entirely in the browser) would have a greater impact in reducing the amount of data being transferred to the server. However, for the purposes of this blog post (and also because it leads to a more complex discussion on how the application architecture can/should evolve and what this feature looks like in the future), we’re going to sidestep that discussion and focus on what benefits data compression may offer.
Compression with pako
I was more than ready to implement a compression algorithm, but was happy to discover pako, which does zlib compression. Compressing (i.e. deflating) with pako is very simple, below I encode the HTML string to UTF8 via TextEncoder.encode() (this is because I want UTF8, this isn’t a requirement of pako), which returns a Uint8Array, then use that as the input for pako.deflate(), which also returns a Uint8Array.
const staticHtmlUtf8Arr = (new TextEncoder()).encode(html);
const compressedStaticHtmlUtf8Arr = pako.deflate(staticHtmlUtf8Arr);
Here’s what that looks like in practice, exporting the diagram shown above:

That’s fairly significant, as the data size has been reduced by 1,237,266 bytes (42.77%)!
The final bit for the frontend is sending this to the server. I use a FormData object for the XHR call and, for the compressed data, I put append it as a Blob:
formData.append(
"compressedStaticHtml",
new Blob([compressedStaticHtmlUtf8Arr], {type: 'application/zlib'}),
"compressedStaticHtml"
);
Handling the compressed data server-side with PHP
PHP support zlib compression/decompression via the zlib module. The only additional logic needed server-side is calling gzuncompress() to decompressed the compressed data.
$staticHtml = gzuncompress(file_get_contents($compressedStaticHtmlFile->getFilePath()));
Note that $compressedStaticHtmlFile is an object representing a file pulled from the request (note that FormData will append a Blob in the same manner as a file, so server-side, you’re dealing with the data as a file). The File.getFilePath() method here is simply returning the path for the uploaded file.
Limitations
Compressing and decompressing data will cost CPU cycles and, for zlib and most algorithms, this will scale with the size of the data. So considerations around what the client-side system looks like and the size of the data need to be taken into account. In addition, compression within a browser’s main thread can lead to UI events, reflow, and repaint being blocked (i.e. the page becomes unresponsive). If the compression time is significant, performing it within a web worker instead would be a better path.








