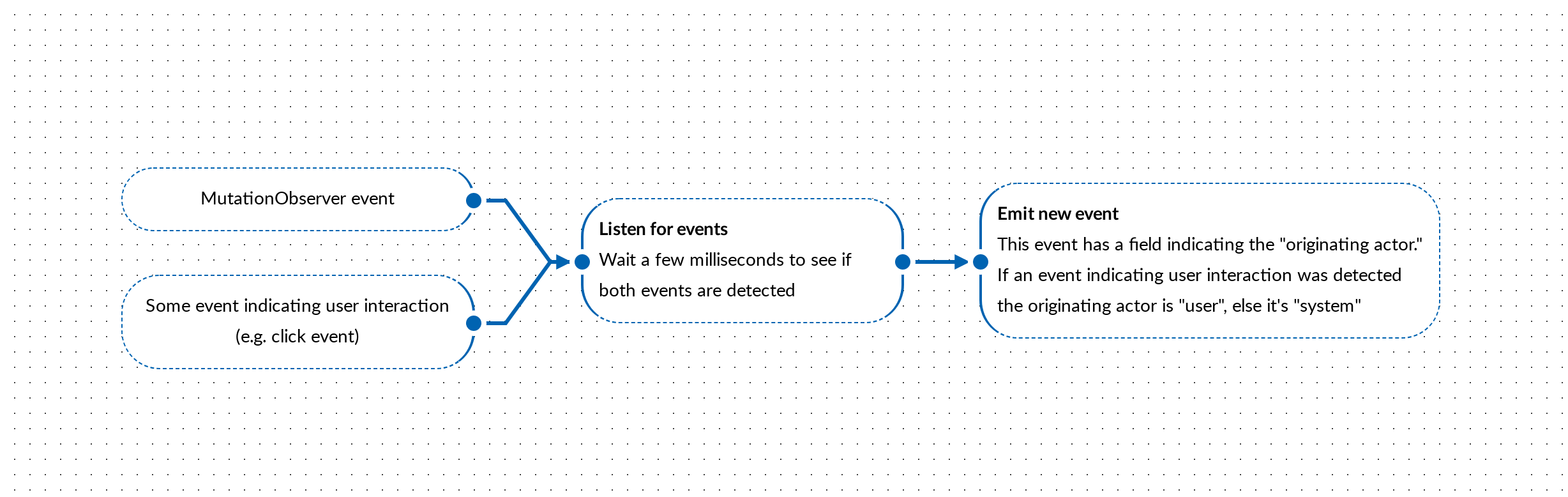
HTTP Strict Transport Security is subtly confusing
Jan 20 2025 · Web Technologies
I stumbled into an issue with HTTP Strict Transport Security (HSTS) earlier this year, which led me down a rabbit hole to truly understand what HSTS was, how it should be used, and why it was introduced to begin with.
What is HTTP Strict Transport Security?
HTTP Strict Transport Security (HSTS) is a standard to force users to connect to a website via HTTPS instead of HTTP.
It’s simply a header that tells the browser only HTTPS connections should be made (i.e. the browser will not attempt HTTP connections), over a period of time:
Strict-Transport-Security: max-age=; includeSubDomains
A user has to visit the HTTPS site at least once for their browser to see the HSTS header and gain the protection offered by it; HSTS relies on a trust on first use scheme.
HSTS aims to address 3 classes of threats:
- Passive Network Attackers: an attacker eavesdropping on an unsecure (HTTP) connection, allowing the attacker to grab user data (e.g. session identifiers from a non-secure cookie, which may have been set in a prior, secure, visit to the site).
- Active Network Attackers: an attacker compromises a node on the network, redirecting the user elsewhere or serving the attacker’s content to the user.
- Web Site Development and Deployment Bugs: a secure (HTTPS) site serving insecure content allowing an attacker to inject compromised content (e.g. serving a malicious script to the user)
HTTP → HTTPS redirects
You could, as an alternative, configure a web server to redirect all HTTP traffic to HTTPS. However, there is a some risk in doing this.
From MDN:

From cio.gov:

It is worth taking a step back here because, while redirects are a concern, RFC 6797, which details HSTS, isn’t specifically focused on redirects, but the broader need to push users to secure (HTTPS) connections.
Jackson and Barth proposed an approach, in [ForceHTTPS], to enable web resources to declare that any interactions by UAs with the web resource must be conducted securely and that any issues with establishing a secure transport session are to be treated as fatal and without direct user recourse. The aim is to prevent click- through insecurity and address other potential threats.
This specification embodies and refines the approach proposed in [ForceHTTPS].
To add some context here, also consider that this RFC is from 2012, close to 12 years old at this point, and the web looked quite different 12 years ago. HTTPS was nowhere near as ubiquitous as it is today. Sites did not always serve HTTPS and, for sites that did, HTTPS was typically provided as an option, not a requirement for all users (see Timeline of HTTPS adoption). Given that context, it’s unsurprising that section 7.2 of the RFC actually has a “SHOULD” behavior recommendation for a redirect:
If an HSTS Host receives an HTTP request message over a non-secure transport, it SHOULD send an HTTP response message containing a status code indicating a permanent redirect…
The takeaway here is that HTTP Strict Transport Security is not necessarily a replacement for an HTTP → HTTPS redirect. An initial connection to the HTTPS version of the site needs to be made for the browser to see the HSTS header and, assuming the risk is acceptable, a redirect is an elegant mechanism to automatically upgrade the connection for users.
You probably need a redirect…
Two mechanisms seemingly eliminate the needs for an HTTP → HTTPS redirect:
- Google’s HSTS preload service
- HTTPS-First Mode
I say “seemingly” because, in practice, you’ll might find you still need a redirect.
Google has long supported a HSTS preload service. The service maintains a list of HSTS sites and browsers will only attempt HTTPS connections for sites on the list. However, adding a site to the preload list might not be appropriate for certain sites or site-owners and a requirement for a site to be added to the preload list is that it implements an HTTP → HTTPS redirect:

Browsers are making a push towards HTTPS-First Mode, attempting an HTTPS connection even if HTTP is specified by the user, and only falling back to HTTP if the HTTPS upgrade fails. However, implementation isn’t quite as cut-and-dry as that. For example, there’s a number of heuristic-based flags in Chrome that determine how and when HTTPS-First Mode is actually engaged, Balanced HTTPS-First Mode, HTTPS-First Mode For Typically Secure Users, etc. So if, for example, you migrate a site to HTTPS and drop HTTP support, don’t be surprised if users are unable to access the site, as an automatic HTTPS upgrade is not performed on bookmarked links (this was a situation I found myself in a few months ago).
The ultimate takeaway here is that, while there is some security risk, you probably support an HTTP → HTTPS redirect. In the future, a strict HTTPS-First Mode may eliminate the need for such a redirect but we’re not there yet.




















{kind=link}