Finding, fetching, and rendering favicons with puppeteer
Apr 5 2020 · Web Technologies
I’ve been working a bit with fetching favicons and noted some of the complexity I encountered:
- The original way to adding favicons to a site, placing
/favicon.icofile in the root directory, is alive and well; browsers will make an HTTP GET request to try and fetch this file. - Within the HTML document,
<link rel="icon" …is the correct way to specify the icon. However, a link tag with<link rel="shortcut icon" …is also valid and acceptable, but “shortcut” is redundant and has no meaning (of course, if you’re trying to parse or query the DOM, it’s a case you need to consider). - Like other web content, the path in a
<link>tag can an absolute URL, with may or may not declare a protocol, or a relative URL. - While there is really good support for PNG favicons, ICO files are still common, even on popular sites (as of writing this Github, Twitter, and Gmail, all use ICO favicons).
- When not using ICO files, they is usually multiple
<link>tags, with different values for thesizesattribute, in order to declare different resolutions of the same icon (ICO is a container format, so all the different resolution icons are packaged together). - The correct MIME type for ICO files is
image/vnd.microsoft.icon, but the non-standardimage/x-iconis much more common. - Despite the popularity of ICOs and PNGs, there’s a bunch of other formats with varying degrees of support across browsers: GIF (animated/non-animated), JPEG, APNG, SVG. Of particular note is SVG, as it’s the only non-bitmap format on this list, and is increasing being supported.
The goal was to generate simple site previews for ScratchGraph, like this:
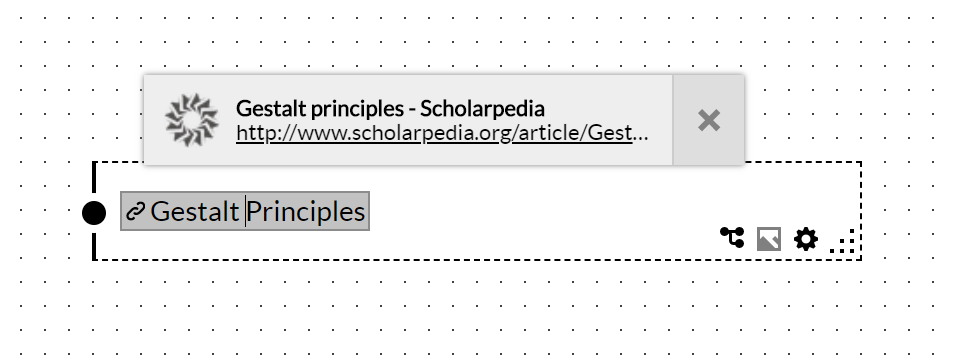
Finding the favicon URL was one concern. My other concern was rendering the icon to a common format, while this isn’t technically necessary, it does lower the complexity in the event that I wanted to do something with the icon, other than just rendering within the browser.
Finding the favicon URL
I wrote the following code to try and find the URL of the “best” favicon using Puppeteer (Page is the puppeteer Page class):
/**
*
* @param {Page} page
* @param {String} pageUrl
* @returns {Promise<String>}
*/
const findBestFaviconURL = async function(page, pageUrl) {
const rootUrl = (new URL(pageUrl)).protocol + "//" + (new URL(pageUrl)).host;
const selectorsToTry = [
`link[rel="icon"]`,
`link[rel="shortcut icon"]`
];
let faviconUrlFromDocument = null;
for(let i=0; i<selectorsToTry.length; i++) {
const href = await getDOMElementHRef(page, selectorsToTry[i]);
if(typeof href === 'undefined' || href === null || href.length === 0) {
continue;
}
faviconUrlFromDocument = href;
break;
}
if(faviconUrlFromDocument === null) {
// No favicon link found in document, best URL is likley favicon.ico at root
return rootUrl + "/favicon.ico";
}
if(faviconUrlFromDocument.substr(0, 4) === "http" || faviconUrlFromDocument.substr(0, 2) === "//") {
// absolute url
return faviconUrlFromDocument;
} else if(faviconUrlFromDocument.substr(0, 1) === '/') {
// favicon relative to root
return (rootUrl + faviconUrlFromDocument);
} else {
// favicon relative to current (pageUrl) URL
return (pageUrl + "/" + faviconUrlFromDocument);
}
};
This will try to get a favicon URL via:
- Try to get the icon URL referenced in the first
link[rel="icon"]tag - Try to get the icon URL referenced in the first
link[rel="icon shortcut"]tag - Assume that if we don’t find an icon URL in the document, there’s a
favicon.icorelative to the site’s root URL
Getting different sizes of the icon or trying to get a specific size is not supported. Also, for URLs pulled from the document via link[rel=… tags, there’s some additional code to see if URL is absolute, relative to the site/document root, or relative to the current URL and, if necessary, construct and return an absolute URL.
The getDOMElementHRef function to query the href attribute is as follows:
/**
*
* @param {Page} page
* @param {String} query
* @returns {String}
*/
const getDOMElementHRef = async function(page, query) {
return await page.evaluate((q) => {
const elem = document.querySelector(q);
if(elem) {
return (elem.getAttribute('href') || '');
} else {
return "";
}
}, query);
};
Fetching & rendering to PNG
Puppeteer really shines at being able to load and render the favicon, and providing the mechanisms to save it out as a screenshot. You could attempt to read the favicon image data directly, but there is significant complexity here given the number of different image formats you may encounter.
Rendering the favicon is relatively straightfoward:
- Render the favicon onto the page by having the Page goto the favicon URL
- Query the
imgelement on the page - Make the Page’s
document.bodybackground transparent (to capture any transparency in the icon when we take the screenshot) - Take a screenshot of that
imgelement, such that a binary PNG is rendered
Here is the code to render the favicon onto the page:
/**
*
* @param {Page} page
* @param {String} pageUrl
* @returns {ElementHandle|null}
*/
const renderFavicon = async function(page, pageUrl) {
let faviconUrl = await findBestFaviconURL(page, pageUrl);
try {
console.info(`R${reqId}: Loading favicon from ${faviconUrl}`);
await page.goto(faviconUrl, {"waitUntil" : "networkidle0"});
} catch(err) {
console.error(`R${reqId}: failed to get favicon`);
}
const renderedFaviconElement = await page.$('img') || await page.$('svg');
return renderedFaviconElement;
};
Finally, here’s the snippet to render the favicon to a PNG:
if(renderedFaviconElement) {
const renderedFaviconElementTagName = await (await renderedFaviconElement.getProperty('tagName')).jsonValue();
if(renderedFaviconElementTagName === 'IMG') {
await page.evaluate(() => document.body.style.background = 'transparent');
}
const faviconPngBinary = await renderedFaviconElement.screenshot(
{
"type":"png",
"encoding": "binary",
"omitBackground": true
}
);
}
EDIT 4/7/2020: Updated code snippets to correctly handle SVG favicons. With SVGs, an <svg> element will be rendered on the page (instead of an <img> element). Also, there is no <body> element, as the SVG is rendered directly and not embedded within an HTML document, and hence no need to set the document’s body background to transparent.
EDIT 1/10/2022: Fix source code snippets to reflect that pageUrl is the variable with the URL of the page, not src.







