Pushing computation to the front: video snapshots
Avishkar Autar · Aug 16 2020 · Web Technologies
Video and the Canvas API
The Canvas API is surprising versatile. The image parameter of the CanvasRenderingContext2D.drawImage() method will accept images from a number of different sources including an HTMLVideoElement. I touched on this a bit in a previous post about processing the data from video streams, however HTMLVideoElement can also handle loading and rendering video files, with all modern browsers capable of tackling the non-trivial tasks of decoding and rendering H.264 MP4 or VP8/VP9 WebM content (and, of course, you get all the benefits of the client’s GPU hardware that the browser takes advantage of). This opens up the possibility of capturing frames from video files which can be used for preview images, poster images, or substituting in an image when video playback isn’t possible (e.g. for a print layout, which is the issue I’ve run into with ScratchGraph).
Setting up the HTMLVideoElement
This is fairly standard, here we’ll load an H.264 MP4 with the filename “test.mp4”:
const video = document.createElement('video');
const videoSource = document.createElement('source');
videoSource.setAttribute('type', 'video/mp4');
videoSource.setAttribute('src', 'test.mp4');
video.appendChild(videoSource);
For reference, here’s the test video:
Next, we want to seek to a point in the video where we want to capture the frame and also bind to an event that’ll tell us when we’re able to read the frame data from the HTMLVideoElement. The seeked event works well. The other potentially viable option is the loadeddata event, but I ran into some issues here, which I’ll describe later.
video.addEventListener('seeked', function(e) {
// capture the video frame at the point seeked to...
});
// seek to 2s
video.currentTime = 2;
Render the frame onto a canvas
The Canvas API makes this really easy and the process mirrors what’s described in the post on thumbnail generation:
/**
*
* @param {HTMLVideoElement} video
* @param {Number} newWidth
* @param {Number} newHeight
* @param {Boolean} proportionalScale
* @returns {Canvas}
*/
videoFrameToCanvas: function(video, newWidth, newHeight, proportionalScale) {
if(proportionalScale) {
if(video.videoWidth > video.videoHeight) {
newHeight = newHeight * (video.videoHeight / video.videoWidth);
}
else if(video.height > video.videoWidth) {
newWidth = newWidth * (video.videoWidth / video.videoHeight);
}
else
{}
}
const canvas = document.createElement('canvas');
canvas.width = newWidth;
canvas.height = newHeight;
const canvasCtx = canvas.getContext('2d');
canvasCtx.drawImage(video, 0, 0, newWidth, newHeight);
return canvas;
}
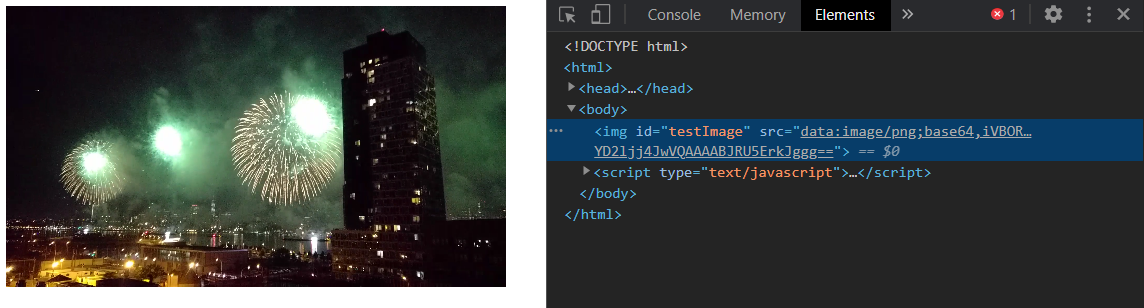
I added this method to the canvas-image-transformer library; referencing the method we can now flesh out the seeked event handler. For this test, we’ll also render out what’s on the canvas to an <img> element in the document to see what’s been captured.
video.addEventListener('seeked', function(e) {
// capture the video frame at the point seeked to
const frameOnCanvas = CanvasImageTransformer.videoFrameToCanvas(video, 500, 500, true);
document.getElementById('testImage').src = frameOnCanvas.toDataURL();
});
frameOnCanvas is a canvas with the captured frame, and here’s what it looks like transformed & rendered into an <img> element:
Issues
- Something not immediately obvious is that the
seekedevent is not fired ifvideo.currentTime = 0(i.e. you want to seek to the first frame of a video). However, you can use a very small time value (e.g.video.currentTime = 0.000000001), which will typically seek to the first frame in most cases. That said, it is a hacky/non-elegant solution. - There are cross-browser issues with the
loadeddataevent. In Firefox, you will only get a frame capture if you don’t seek. If you do attempt to seek, you’ll get a empty frame and the canvas will have a transparent image. Conversely, in Chrome (and other Webkit-based browsers), you will only get a frame if you do seek. The standard states that the event should be fired when “the user agent can render the media data at the current playback position for the first time” which seem to indicate an implementation flaw in both browsers. - The test video was taken on my phone and the frames themselves are upsided-down, this is typical with smartphone videos as it’s expected that playback will take into account metadata indicating orientation. In Firefox, this isn’t taken into account when using
CanvasRenderingContext2D.drawImage()withHTMLVideoElement, so you get an upsided-down image on the canvas.
Alternatives & limitations
I couldn’t think of a ton of options for decoding H.264 or VP8/VP9. If you’re looking to create something yourself, a server-side service invoking FFmpeg seems like the best option. I played around with Puppeteer, but Puppeteer comes with Chromium, which lacks the audio and video support you get out-of-the box with Chrome. Although, installing and using Chrome server-side with Puppeteer has potential.
There are also third-party services which can handle video decoding and transcoding, and those are solid server-side options.
As with thumbnail generation, here again we’re looking at workloads that have potential to be moved to the frontend, where you have hardware better suited for graphics work and the possibility of reducing backend complexity. On the other hand, the same limitations comes into play, as you have less control over the execution environment and no clear path for backfill or migration needs.