One annoying problem I began encountering with ScratchGraph a while ago was fake signups. Every so often I would notice a new account created but there would be no interaction on the site beyond account creation. I’d also notice some other errors in the application log, as the spam bot would attempt to fill in and submit every form on the landing page, so I’d get login failure and reset account errors as well. At first, I figured I could just ignore this; metrics would be a bit off, I’d have a bounced welcome email from time to time, and I could just purge the few fake accounts at some point the future. Unfortunately it got to the point where there were so many fake accounts being created that figuring out if an account was real took more effort, there was a lot of garbage in the database and logs and, perhaps most importantly, welcome emails being sent out would be bounced or flagged as spam, dragging down my email reputation and increasing the possibility of emails going to spam.
A solution
There’s a bunch of blog posts from email marketing services detailing this issue, e.g. Mailchip, Folderly. There’s usually a common few solutions mentioned:
I wanted to minimize dependencies and additional integrations, so no ReCAPTCHA
Email confirmation seemed like too heavy of a lift and I disliked the idea of having a user jump from the application to their inbox
Throttling kinda makes sense (I could see if other forms were submitted around the same time, with the same email address, and flag the account), this is possible but not trivial for a PHP application where you don’t have service-level jobs running in the background
So, I added a honeypot field on the signup form. In practice, I wrapped a text input in a hidden div and I gave the input the name fullname. A user’s full name is also not requested/collected during sign up and I figured the spambot may try to gauge what to do with the field based on its name, so I should give it a realistic name. On the backend, if fullname is non-empty, the request still succeeds (HTTP 200), but an account is not created. Instead, email and IP address are logged in a table for spam signups (I figure I might be able to do something with this data at some point).
Efficacy
I was somewhat skeptical as to how well a honeypot field on the signup form would work, I was imaging spambots being incredibly sophisticated, maybe noticing the field was hidden or there was no change on the frontend. Turns out this is not the case or at least not the case for the spambots I was facing. From what I can tell, this relatively simple approach has detected and caught all fake signups from spambots.
I imagine there’s a shelf life to this solution (happy to be wrong) but, when it starts to fail, I can always integrate another approach such as throttling or ReCAPTCHA.
PHP’s strip_tags() method will strip away tags but makes no attempt to introduce whitespace to separate content in adjacent tags. This is an issue with arbitrary HTML as adjacent block-level elements may not have any intermediate whitespace and simply stripping away the tags will incorrectly concatenate the textual content in the 2 elements.
For example, running strip_tags() on the following:
<div>the quick brown fox</div><div>jumped over the moon</div>
… will return:
the quick brown foxjumped over the moon
This is technically correct (we’re stripped away the <div> tags) but having no whitespace between “fox” and “jumped” means we’ve transformed the content such that we’ve lost semantic and presentational details.
The Solution
There’s 2 ways I can see to fix this behavior:
Pre-process the HTML content to ensure or introduce whitespace between block-level elements
Don’t use strip_tags() and utilize a method that better understands the need for spacing between elements
I’ll focus on the latter because that’s the avenue I went down and I didn’t consider pre-processing at the time.
Pulling together a quick-and-dirty parser, I wrote the following. It’s worth noting that still still doesn’t really consider what the tags are (e.g. whether they’re inline or block) but allows the caller to specify a string ($tagContentSeparator), typically some whitespace, that is inserted between the stripped away tags:
<?phpclassHTMLToPlainText{
const STATE_READING_CONTENT = 1;
const STATE_READING_TAG_NAME = 2;
staticpublicfunctionconvert(string $input, string $tagContentSeparator = " "): string{
// the input string as UTF-32
$fixedWidthString = iconv('UTF-8', 'UTF-32', $input);
// string within tags that we've found
$foundContentStrings = [];
// buffer for current content being read
$currentContentString = "";
// flag to indicate how we should interpret what we're reading from $fixedWidthString// .. this is initially set to STATE_READING_CONTENT, as we assume we're reading content from the start, even// if we haven't encountered a tag (e.g. string that doesn't contain tags)
$parserState = self::STATE_READING_CONTENT;
// method to add a non-empty string to $foundContentStrings and reset $currentContentString
$commitCurrentContentString = function()use(&$currentContentString, &$foundContentStrings){
if(strlen($currentContentString) > 0) {
$foundContentStrings[] = trim($currentContentString);
$currentContentString = "";
}
};
// iterate through characters in $fixedWidthString// checking for tokens indicating if we're within a tag or within contentfor($i=0; $i<strlen($fixedWidthString); $i+=4) {
// convert back to UTF-8 to simplify character/token checking
$ch = iconv('UTF-32', 'UTF-8', substr($fixedWidthString, $i, 4));
if($ch === '<') {
$parserState = self::STATE_READING_TAG_NAME;
$commitCurrentContentString();
continue;
}
if($ch === '>') {
$parserState = self::STATE_READING_CONTENT;
continue;
}
if($parserState === self::STATE_READING_CONTENT) {
$currentContentString .= $ch;
continue;
}
}
$commitCurrentContentString();
return implode($tagContentSeparator, $foundContentStrings);
}
}
Note that the to/from UTF-8 ↔ UTF-32 isn’t really necessary, I initially did the conversion as I was worried about splitting a multibyte character, but this isn’t possible given how the function reads the input string.
Now if we take the following HTML snippet:
<div>the quick brown fox</div><div>jumped over the moon</div>
… rendered in a browser, we get:
… with strip_tags() we get:
the quick brown foxjumped over the moon
… and with HTMLToPlainText::convert() (passing in “\n” for $tagContentSeparator), we get:
the quick brown fox
jumped over the moon
The latter results in text that is semantically correct, as words in different blocks aren’t incorrectly joined. Presentationally we also get a more correct conversion but, the method isn’t really doing anything fancy here, this is due to the calling knowing a bit about the HTML snippet, how a browser would render it, and passing passing in “\n” for $tagContentSeparator.
Limitations / future work
The improvement here is that textual content is pretty preserved when doing a conversion, i.e. we don’t have to worry about textual elements being incorrectly concatenated. However, what I wrote is still lacking in 2 keys areas:
Generally, in terms of presentation, an arbitrary bit of HTML won’t map to what a user sees in a browser. To a certain degree this is an intractable problem, as presentation is based on browser defaults, CSS styles, etc. Also, there are things that simply don’t have a standard representation in plain-text (e.g. bold text, list items, etc.). However, there are cases where sensible defaults might make sense, e.g. stripping away <span> tags but putting newline between <p> tags.
Whitespace is trimmed from content within tags. This may or may not matter depending on application. In my case, I cared about the words and additional whitespace just added bloat even if it was more accurate to what was in the HTML.
EDIT: See part 2 on addressing these limitations and making the code more robust.
I started learning about microservices and seeing momentum the architectural pattern around 2015. A number of developers I worked with at Grovo were enthusiastic about the idea as a solution to a number of scaling issues we were facing. The more I looked around, the more I saw developers across the industry purporting microservices as the new, modern architectural pattern. For some companies, this was natural evolution in their systems architecture, but for many companies, especially smaller startups, the push towards microservices seemed driven by the idea that, despite the cost and difficulties, this was going to be the status quo for leading tech companies and that was the direction they should be headed in. I was on the “smaller startup” side of the industry and, from my vantage point, this perspective didn’t seem to be based on any sort of real engineering analysis but more-so aligning with what was being talked about in the industry, adopting what larger companies (e.g. Netflix) were doing, and a belief that microservices were a silver bullet to scaling issues. Looking back, none of this is too surprising. Following in the footsteps of Big Tech, even when your business is operating at a different scale and your tech problems look very different, or jumping on the hype train for the latest technology (e.g. the “just-got-back-from-a-conference” effect), continues to be prevalent in the industry.
For VC-backed startups, it’s also worth looking at the state of the market around 2014-2015. Venture capital funding in tech shot up along with the size of the deals. Closing a VC round and being pushed to grow was also not out of the ordinary. I’ll hand-wave a bit here, but I think this also led to larger engineering teams, a corresponding overconfidence in what could be tackled, and an underestimation of the difficulties of working within and maintaining a topologically complex architecture.
The lesson in all this is to look at and understand industry dynamics relative to your company and your role. Software isn’t made in a vacuum and the zeitgeist of the industry is a key factor in how engineering decisions are made and what solutions manifest.
Finally, this may all sound cynical and, in terms of the pattern itself, it sort of is. Working on microservices led me to view them as an optimization and not a general pattern for application development. However, building with microservices was also a powerful forcing function to really look at and tackle inefficiencies in infrastructure, deployments, and code structure. In addition, the company-level initiative to push towards microservices highlighted the dynamics by which decisions are made and driven, from industry buzz to company leaders to individual engineers. What I learned from all of this improved my technical work in areas beyond microservices and that’s what I hope to really highlight in this and future posts.
Deployment workflows can vary a lot, but what I’ve tended to find ideal is to tag releases on GitHub (or whatever platform, as most have some mechanism to handle releases), the tag itself being the version number of whatever is being deployed, and having a deployment pipeline orchestrate and perform whatever steps are necessary to deploy the application, service, library, etc. This flow is well supported with git, well supported on platforms like GitHub, and is dead simple for developers to pick up and work with (in GitHub, this means filling out a form and hitting “Publish release”).
npm doesn’t play nicely with this workflow. With npm version numbers aren’t tied to git tags, or any external mechanism, but instead to the value defined in the project’s package.json file. So, trying to publish a package via tagging requires some additional steps. The typical solutions seem to be:
Update the version in package.json first, then create the tag
Use some workflow that include npm version patch to have npm handle the update to package.json and creating the git tag
None of these options are great; versioning responsibility and authority is pulled away from git and, in the process, additional workflow complexity and, in the latter case, additional dependencies are introduced.
Version 0.0.0
In order to publish with npm, keep versioning authority with git, and maintain a simple workflow that doesn’t include additional steps or dependencies, the following has been working well in my projects:
In package.json, set the version number to “0.0.0”; this value is never changed within any git branch and, conceptually, it can be viewed as representing the “dev version” of the library. package.json only has a “non-dev version” for code published to our package repository.
In the deployment pipeline (triggered by tagging a release), update package.json with the version from the git tag.
Most CI systems have some way of getting the tag being processed and working with it. For example, in CircleCI, working with tags formatted like vMAJOR.MINOR.PATCH, we can reference the tag, remove the “v” prefix, and set the version in package.json using npm version as follows:
npm --no-git-tag-version version ${CIRCLE_TAG:1}
Note that this update to package.json is only done within the checked-out copy of the code used in the pipeline. The change is never committed to the repo nor pushed upstream.
Finally, within the deployment pipeline, publish as usual via npm publish
Limitations
I haven’t run across any major limitations with this workflow. There is some loss of information captured in the git repository, as the version in package.json is fixed at 0.0.0, but I’ve yet to come across that being an issue. I could potentially see issues if you want to allow developers to do deployments locally via npm publish but, in general, I view local deployments as an anti-pattern when done for anything beyond toy projects.
Picking up from being able to successfully write images to the Bitfenix ICON display, I started looking into how to render textual content. Despite their lack of versatility, using a bitmap font was a natural option: they’re easy to work with, they’re a good fit for fixed-resolution displays, and rendering is fast.
I pulled up the following bitmap font from an old project (I don’t remember the source used to create this):
A few points about this font:
Each character glyph is 16×16, with a total of 256 characters in the 256×256 bitmap
Characters are arranged/indexed left-to-right, top-to-bottom, and the index of a 16×16 block will correspond with an ASCII or UTF8 codepoint value (e.g. the character at index 33 = “!”, which also maps to UTF8 codepoint 33)
Despite space for 256 characters, there’s a very limited set of characters here, but there’s enough for simple US English strings
While each character is 16×16 pixels, this is not a monospaced font, there is data for accompanying widths for each character
The glyphs are simply black and white (i.e. there’s no antialiasing on the character glyphs, we can simply ignore black pixels and not worry about blending into the background)
Rendering Strings
We need to render characters from the bitmap font onto something. We could create a new image but, building upon what was done in part 1, I decided to render atop this background image. The composite of the background image + characters will be the image written to the ICON display.
To start, we’ll load the background image just as we did in part 1, but we need to make it mutable, as we’ll be writing character pixels direct to it:
// Background image needs to be 240x320 (24bpp, no alpha channel)letmut background_image = reduce_image_to_16bit_color(&load_png_image("assets/1.png"));
Next, we’ll load the font PNG in the same manner (it doesn’t need to be mutable, as we’re not modifying the character pixels):
let font_image = reduce_image_to_16bit_color(&load_png_image("assets/fonts/font1.png"));
To handle text rendering a TextRenderer struct is declared with the rendering logic encapsulated in TextRenderer.render_string(), which loops through each character in the input string, looks up the location of the character in the bitmap font, and renders the 16×16 block of pixels for the character onto the background image. The x-location of where to render a character is incremented by the width of the previous character (found via lookup into TextRenderer::font_widths vector).
pubstructTextRenderer {
font_widths: Vec<u8>,
}
impl TextRenderer {
pubfnnew() -> TextRenderer {
TextRenderer {
font_widths: build_font_width_vec()
}
}
pubfnrender_string(&self, txt: &str, x: u64, y: u64, fontimg: &[u8], outbuf: &mut [u8]) {
// x position of where character should be renderedletmut cur_x = x;
for ch in txt.chars() {
// From codepoint, lookup x, y of character in font and width of character from self.font_widthslet ch_idx = ch asu64;
let ch_width = self.font_widths[(ch asu32 % 256) asusize];
let ch_x = (ch_idx % 16) * 16;
let ch_y = ((ch_idx asf32 / 16.0) asu64) * 16;
// For each character, copy the 16x16 block of pixels into outbuffor fy in ch_y..ch_y+16 {
for fx in ch_x..ch_x+16 {
let fidx: usize = ((fx + fy*256) * 2) asusize;
let fdx = fx - ch_x;
let fdy = fy - ch_y;
let outbuf_idx: usize = (((cur_x + fdx) + (y + fdy)*240) * 2) asusize;
// If the pixel from the font bitmap is not black, write it out to outbufif fontimg[fidx] != 0x00 && fontimg[fidx+1] != 0x00 {
outbuf[outbuf_idx] = fontimg[fidx];
outbuf[outbuf_idx + 1] = fontimg[fidx + 1];
}
}
}
cur_x = cur_x + (ch_width asu64);
}
}
}
The TextRenderer::font_widths vector is built from the build_font_width_vec() method, which simply builds and returns a vector of hardcoded values for the character widths:
The final piece is simply creating a TextRenderer instance and calling render_string() with the necessary parameters. Here we’ll write out “Hello world!” to position 10, 20 on the display:
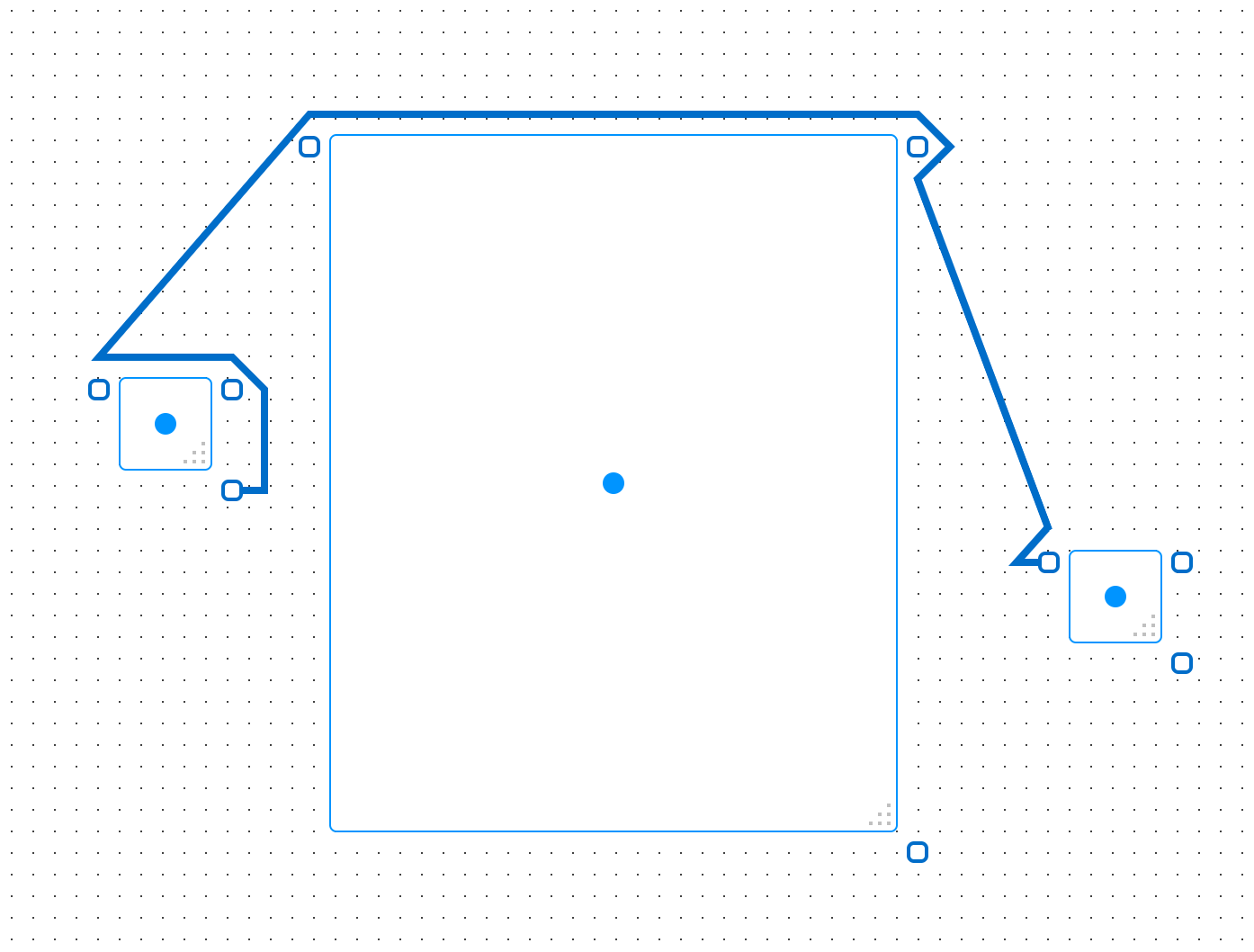
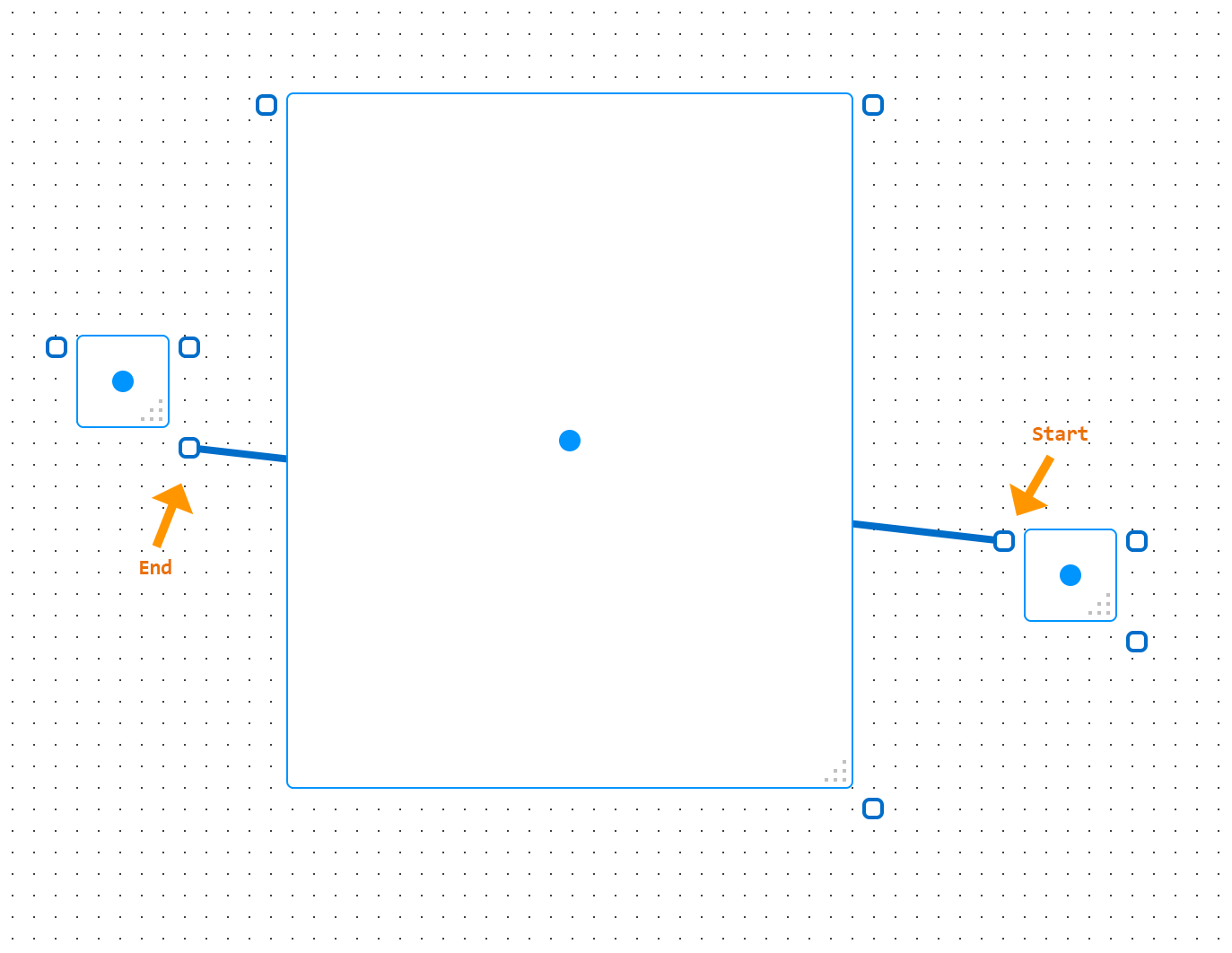
With GraphPaper, generating path with the A* algorithm I ran into some interesting cases where the algorithm would fail to generate a path between the start and end points:
Note that the path should go around, not directly across the big rectangle in the center.
There’s a few things being masked here, as GraphPaper will always try to produce a result, even if it’s non-optimal. So we need to disable:
The mechanism that makes a path directly from start to end if there’s a failure in generating a path
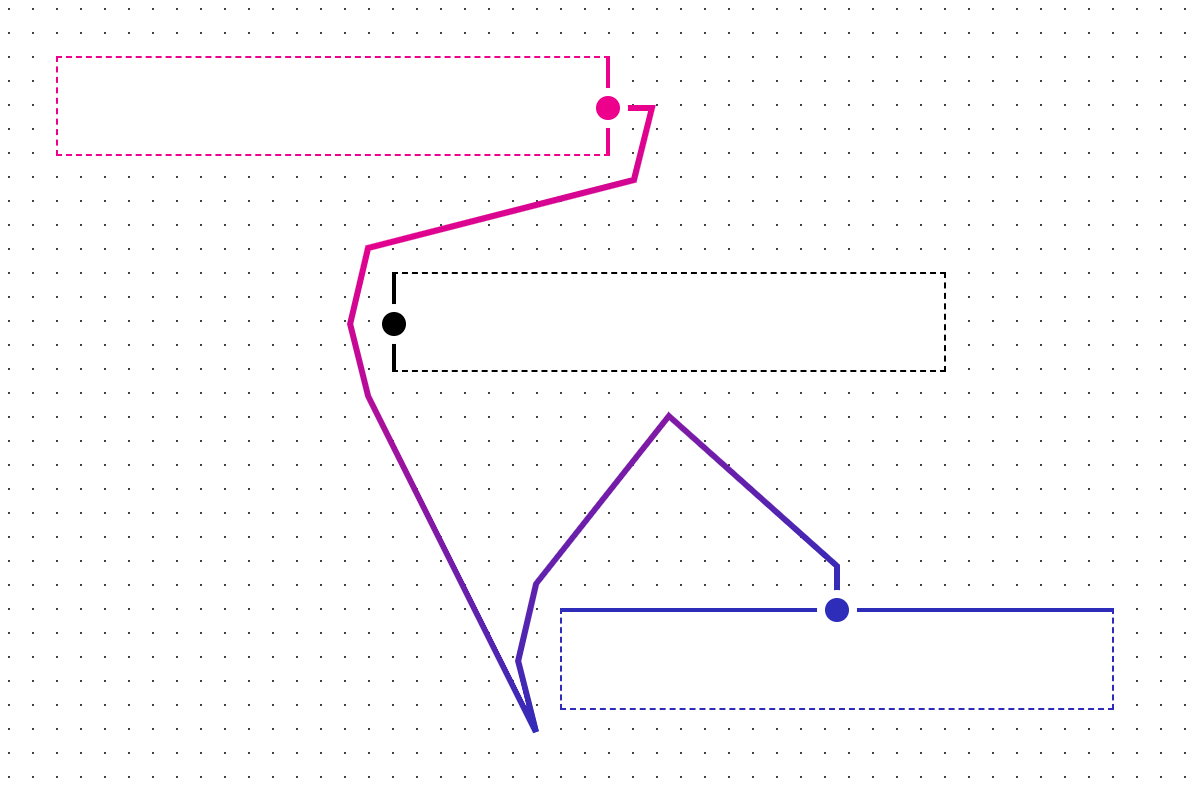
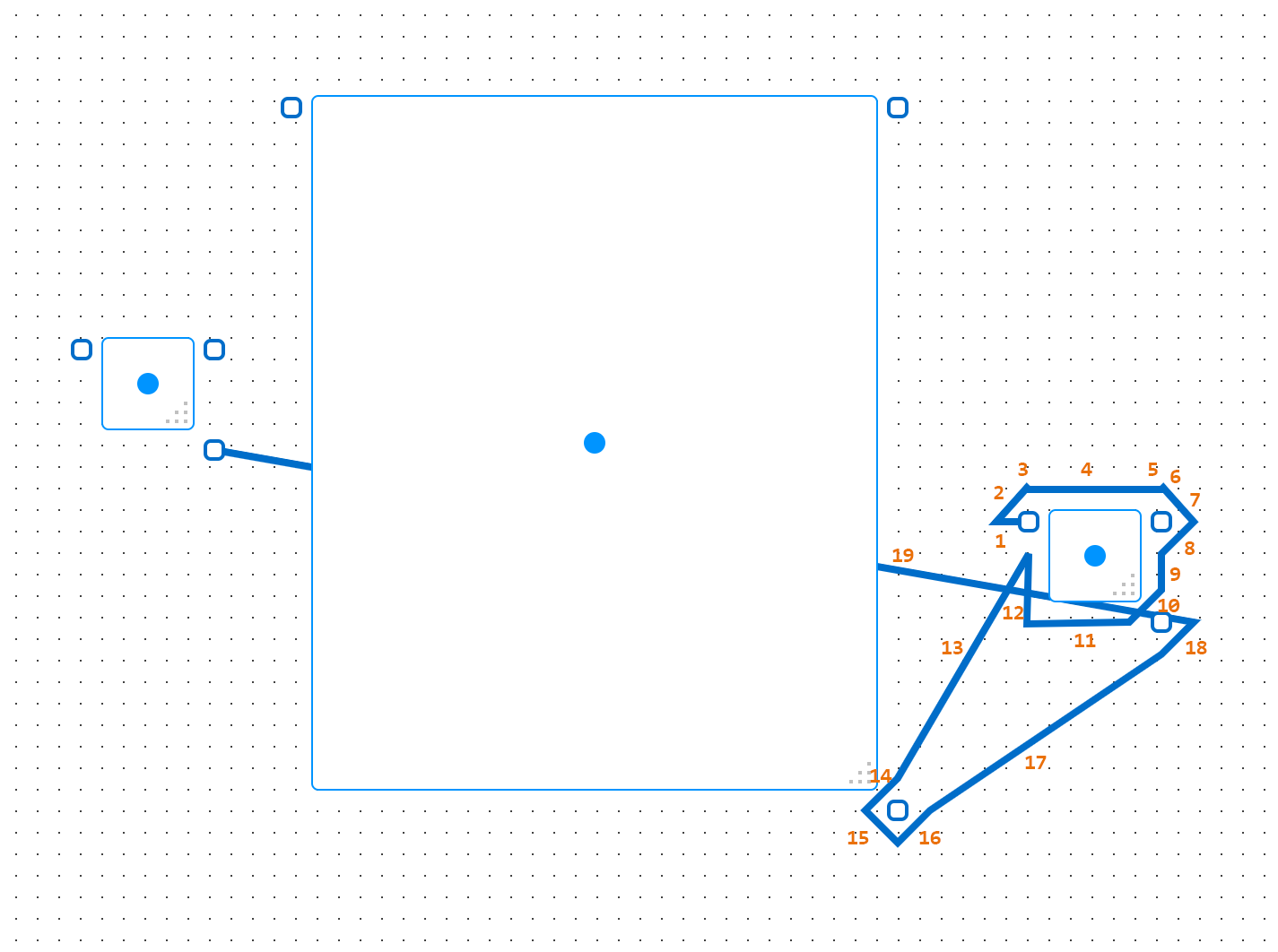
With these disabled, and some annotations showing the order in which the path segments were generated, we can get a better idea of what’s happening:
Here we see that the algorithm generates a path that loops around its adjacent object (1-12), the path moves away from the object (13-14), then moves right back towards the object (15-18), then we’re out of accessible routing points, so we have a failure and we end the path by going directly to the endpoint. It’s important to note that routing points are not grid points here, they’re points designated around objects (the rectangles with the dots in the center) and anchors (the rectangles where paths start and end).
Why is this happening?
This might seem like a bug in the A* implementation but, as far as I can tell, the algorithm is performing as it should and the issue here comes down to the path cost computation done in the main loop. A* doesn’t actually define how to compute cost, but GraphPaper uses run-of-the-mill Euclidean distance as a metric.
In the A* main loop, the cost of going from our current point to a given point, n, is given by:
g(n) is the total length of the path from the starting point to n (sum of the length of all pieces of the path). In practice, we keep track of the current path length, so we only need to compute and add the straight-line length from current to n:
h(n) is the straight-line length from n to the goal:
The issues we’re seeing surface as a result of f(n) being based solely on distance computations, note that:
We may have a good point, n, it’s close to our goal but requires a large jump from our current location, the large increase in g(n) leads to another, closer, point being prioritized
We may have a bad point, n, it’s further from our goal but only requires a small jump from our current location, h(n) increases a bit but the relatively small increase in g(n), leads to this point being prioritized over a better one
The implication here is also that shorter jumps become preferable, even if we end up going in the opposite direction of the goal, as such jumps are safer (i.e. less likely to lead to an blocked/invalid path).
Smarter routing
To improve the routing, I wanted to adjust the cost computation such that moving to points that and in the direction of (and thus closer) to the goal are prioritized, so I introduced a new term, t(n), in the cost computation:
To compute t(n), we first compute the dot product of 2 normalized vectors:
vecCurrentTo(endpt): from current to the endpoint, representing the ideal direction we should head in
vecCurrentTo(n): from current to n, representing the direction to n
The dot product ranges from [-1, 1]; tending to -1 when n is in the opposite direction of the ideal, and tending to 1 when n is in the same direction as the ideal.
We then scale the dot product result as we can’t just bias our overall cost, f(n), by a range this small, so we scale by the straight-line length from current to n. Using this length as a scaling factor also serves to bias towards longer paths in good/positive directions directions.
In code, the functions g(n), h(n) and t(n) components are computed like this:
// g(n) = length/cost of _startPoint to _vp + _currentRouteLengthconst currentToVisibleLength = (new Line(currentPoint, visiblePt)).getLength();
let gn = currentToVisibleLength + _currentRouteLength;
// h(n) = length/cost of _vp to _endPointlet hn = (new Line(visiblePt, _endPoint)).getLength();
// t(n) = // a. get the relationship between the 2 vectors (dot product)// b. scale to give influence (scale by currentToVisibleLength)// .. using currentToVisibleLength as scaling factor is influence towards longer paths in good directions vs shorter paths in bad directionsconst vecToTargetIdeal = (new Vec2(_endPoint.getX() - currentPoint.getX(), _endPoint.getY() - currentPoint.getY())).normalize();
const vecVisibleToEndpt = (new Vec2(visiblePt.getX() - currentPoint.getX(), visiblePt.getY() - currentPoint.getY())).normalize();
const tn = vecToTargetIdeal.dot(vecVisibleToEndpt) * currentToVisibleLength;
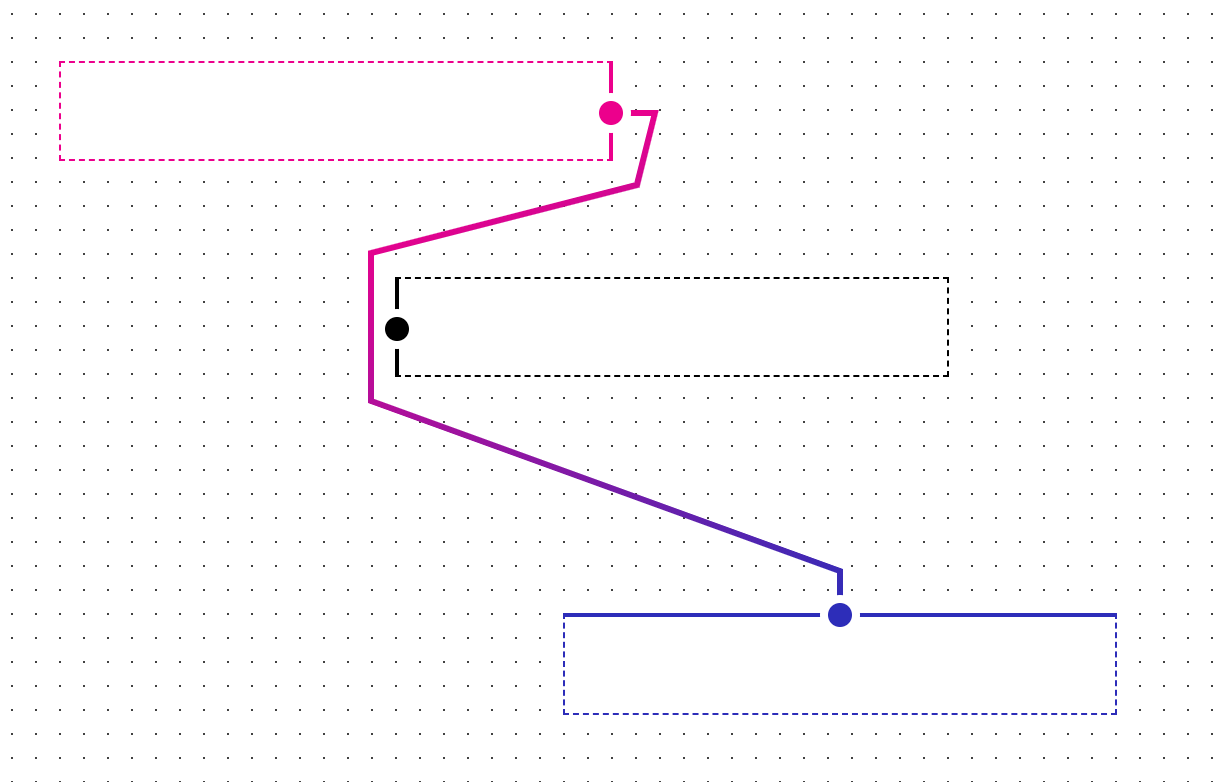
With the updated path cost computation, we successful get a path to the endpoint and, even with path optimization off, we get a much better path overall with less unnecessary points in the path and no looping around objects:
It’s also noting how this performs as the position of the object changes (again, path optimization is disabled and the mechanism that makes a path directly from start to end on routing failure is also disabled):
Without t(n)
With t(n)
In pretty much every case, applying the t(n) factor to the path computation produces a better path with no failures in routing to the endpoint.
The A* algorithm, using a straight-line distance heuristic function, is great in terms of performance, but yields a number of cases where the paths produced are not optimal.
For example, here is a path created in ScratchGraph using GraphPaper (the underlying library used for creating the connectors):
I suspect the non-optimal result is even more pronounced here given that the path is determined based on specific routing points that exist around the objects (you can spot these as the inflection points in the path), instead of a uniform grid. That said, I don’t want to use a uniform grid; while it’s likely a non-issue with A*, there is also the cost of computing which routing points are accessible vs blocked, and that cost grows quickly as the possible number of routing points grow.
An approach that works well, and doesn’t drastically increase the cost of path computation, is simplifying the generated path by checking if corresponding points in the path are visible to each other. If so, we can remove the intermediate points, and simply connect those 2 points together. Here’s a snipped from the GraphPaper codebase:
Begin with the points start (first point in the path) and end (last point in the path).
Relative to start, check if the other points in the path are visible to it (in the code above, we iterate backwards from the endpoint). If we find that start is visible to another point, we eliminate the intermediate points from the path.
Once we get to end being the point after start, update start to the next point in the path and reset end to whatever the last point in the path is.
Repeat the latter 2 steps until we’ve checked all corresponding points in the path (start is the point directly preceding end).
Optimizing the path shown above with this method yields an optimal path:
In terms of performance, the cost is based on the number of points in the path and the cost of whatever computation the _arePointsVisibleToEachOther() function does. For my use-cases, paths have relatively few points and _arePointsVisibleToEachOther() consists of a number of fairly fast line-line intersection checks, so the method is fairly cheap and there’s no significant decrease in performance when generating paths.
Content from a web server being automatically gzipped (via apache, nginx, etc.) and transferred to the browser isn’t anything new, but there’s really nothing in the way of compression when going in the other direction (i.e. transferring content from the client to the server). This is not too surprising, as most client payloads are small bits of textual content and/or binary content that is already well compressed (e.g. JPEG images), where there’s little gain from compression and you’re likely to just waste CPU cycles doing it. That said, when your frontend client is a space for content creation, you’re potentially going to run into cases where you’re sending a lot of uncompressed data to the server.
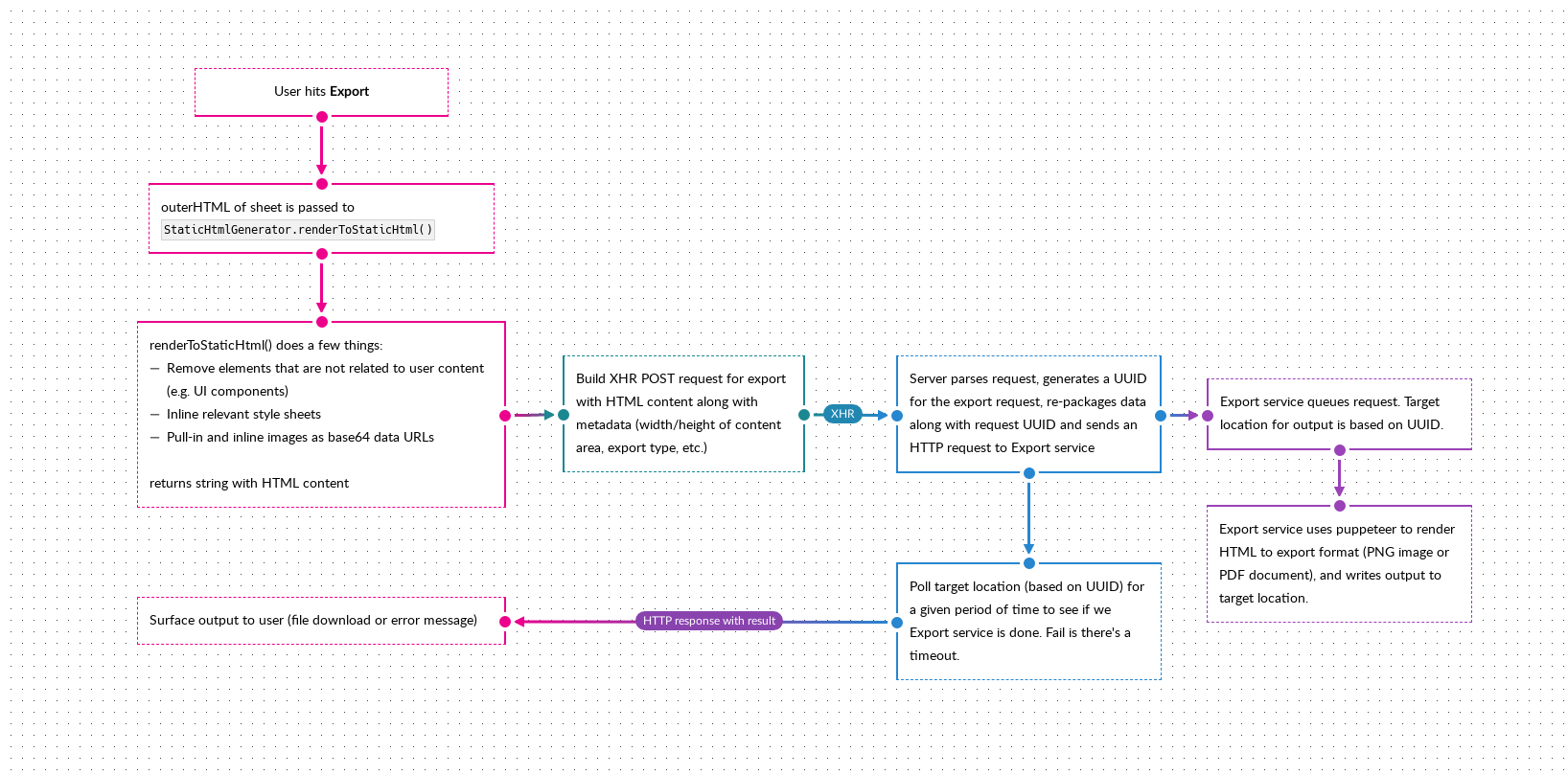
Use-case: ScratchGraph Export
ScratchGraph has an export feature that essentially renders the page (minus UI components) as a string of HTML. This string packaged along with some metadata and sent to the server, which sends it to a service running puppeteer, that renders the HTML string to either an image or a PDF. The overall process looks something like this:
The HTML string being sent to the server is relatively large, a couple of MBs, due to:
The CSS styles (particularly due to external resources being pulled in and inlined as base64 URLs)
The user simply having lots of content
To be fair, it’s usually the former rather than the latter, and optimizing to avoid the inlining of resources (the intent of which was to try and do exports entirely in the browser) would have a greater impact in reducing the amount of data being transferred to the server. However, for the purposes of this blog post (and also because it leads to a more complex discussion on how the application architecture can/should evolve and what this feature looks like in the future), we’re going to sidestep that discussion and focus on what benefits data compression may offer.
Compression with pako
I was more than ready to implement a compression algorithm, but was happy to discover pako, which does zlib compression. Compressing (i.e. deflating) with pako is very simple, below I encode the HTML string to UTF8 via TextEncoder.encode() (this is because I want UTF8, this isn’t a requirement of pako), which returns a Uint8Array, then use that as the input for pako.deflate(), which also returns a Uint8Array.
const staticHtmlUtf8Arr = (new TextEncoder()).encode(html);
const compressedStaticHtmlUtf8Arr = pako.deflate(staticHtmlUtf8Arr);
Here’s what that looks like in practice, exporting the diagram shown above:
That’s fairly significant, as the data size has been reduced by 1,237,266 bytes (42.77%)!
The final bit for the frontend is sending this to the server. I use a FormData object for the XHR call and, for the compressed data, I put append it as a Blob:
formData.append(
"compressedStaticHtml",
new Blob([compressedStaticHtmlUtf8Arr], {type: 'application/zlib'}),
"compressedStaticHtml"
);
Handling the compressed data server-side with PHP
PHP support zlib compression/decompression via the zlib module. The only additional logic needed server-side is calling gzuncompress() to decompressed the compressed data.
Note that $compressedStaticHtmlFile is an object representing a file pulled from the request (note that FormData will append a Blob in the same manner as a file, so server-side, you’re dealing with the data as a file). The File.getFilePath() method here is simply returning the path for the uploaded file.
Limitations
Compressing and decompressing data will cost CPU cycles and, for zlib and most algorithms, this will scale with the size of the data. So considerations around what the client-side system looks like and the size of the data need to be taken into account. In addition, compression within a browser’s main thread can lead to UI events, reflow, and repaint being blocked (i.e. the page becomes unresponsive). If the compression time is significant, performing it within a web worker instead would be a better path.
A few weeks ago, news that using Excel resulted in the loss of ~16,000 coronavirus cases in England due to a 65K row limit in XLS files, sparked a number of tweets around how Excel isn’t a database. There’s a lot to cringe at here, but saying Excel or, more precisely, spreadsheets aren’t databases and using a “proper database” would have prevented a failure is incredibly reductive.
Definition
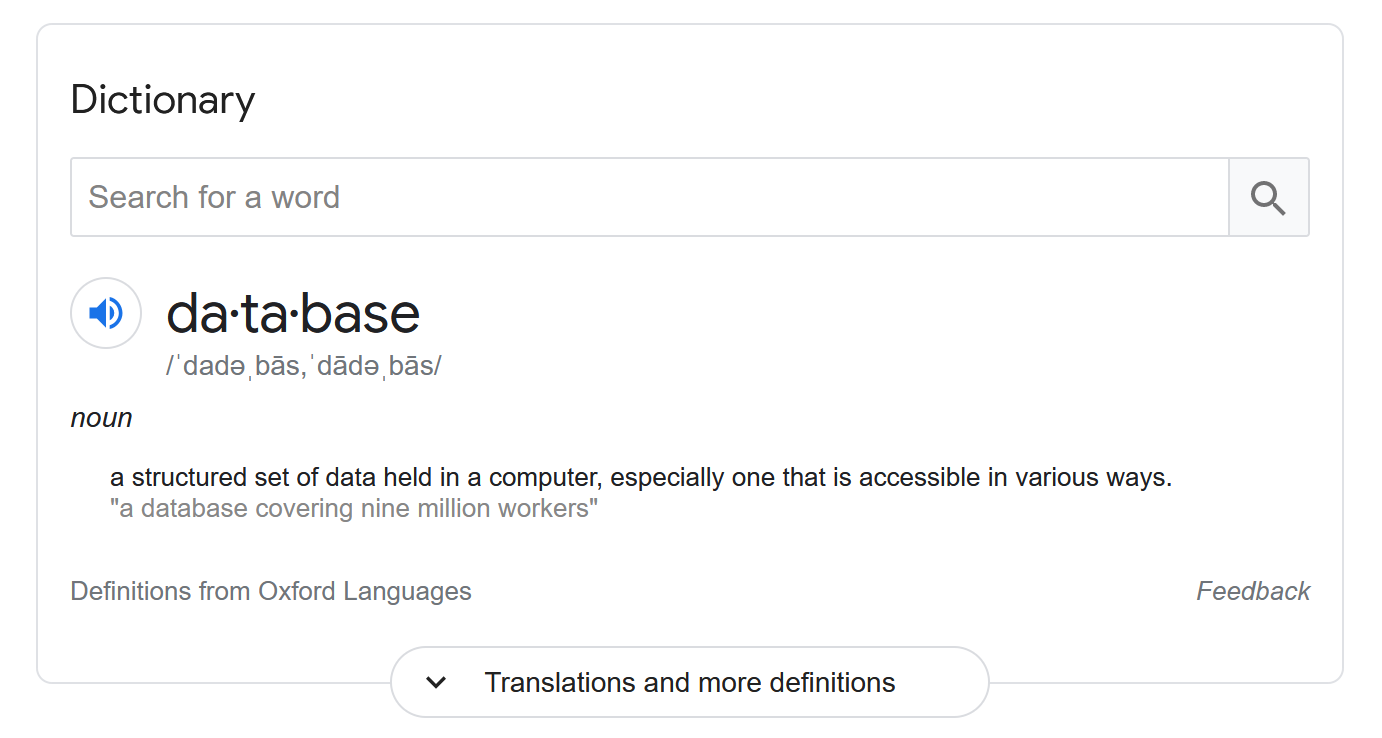
To start, it’s worth looking at what the definition of “database” actually is:
At least from that definition, I think it’s fair to say spreadsheets are databases. They’re primitive, there’s little-to-nothing in the way of concurrency, security, constraints, etc., but they are databases.
In software engineering, the term “database” is typically shorthand for a relational database, but that feels more and more problematic, as we now see many more databases in use now that aren’t relational (Cassandra, Mongo, DynamoDB, etc.). Even S3 now serves as a foundational basis for many databases.
System Considerations
Beyond definitions, what’s also interesting here is that tooling and database choice is never a simple equation for a non-trivial data system; there’s a host of considerations that come into play. Here’s a few that pop into my mind:
Interfacing: Who’s accessing and/or manipulating data in the system? Sophisticated data systems and bespoke interfaces are powerful, but they require training and expertise, and there’s typically a higher maintenance burden. Leveraging common and ubiquitous tooling can be beneficial when it comes to interfacing needs for a larger audience. This comment on ArsTechnica points out that the “proper tools” are inordinately complex and not something a typical end-user can pick-up and understand easily, and I think that’s a fair assessment of the product landscape.
System limits: every data system has limits, some are explicit and obvious, some are not. It’s also not surprising to bump into limits due how a database is setup or how a schema is designed. Hitting a 65K row limit is frustrating and problematic, but so is discovering a value is truncated because the field length was set too small or an incorrect type was used.
Cost: What is the cost of the technical infrastructure? What about the cost of the people needed maintain the system? Unsurprisingly, more sophisticated and complex systems will cost more.
Failure modes: What are some common ways this system fails? What does it take to recover and get back to normal operations? With simple systems you tend to just hit hard limits, but more complex systems fail in a multitude of ways.
Time: When does this need to be shipped and what compromises need to be made? When you don’t have weeks or months to design and prototype, leveraging per-existing and proven method is typically the path of least resistance.
It’s perhaps easy to point to some of the issues that come into play with Excel and spreadsheets, but any data system will have its fair share of limits and risks, along with any potential benefits.
A proper way to deal with clipboard access has been a dream for web developers for years. There’s out-of-the-box browser support, via keyboard shortcuts and content menu commands, for <input>, <textarea>, or elements with the contenteditable attribute. However, for more complex interactions or dealing with application-defined, non-textual objects (e.g. something composed of multiple DOM elements that is manipulable by the user, such as the ScratchGraph notes and connectors shown below) we need to start looking at the available Javascript APIs.
Clipboard API vs document.execCommand() + paste event
The bad news is that document.execCommand() (using the “cut”, “copy” commands) is still the de-facto way of writing to the clipboard, despite this method being deemed obsolete. The good news is that there does seems to be good progress, in terms of stability and browser implementation, of the Clipboard API.
For reading from the clipboard, the paste event seems to be the best way to go, however there is the inherent limitation that this event will only be triggered by “paste actions” from the browser’s interface (e.g. the use hitting Ctrl + V). Again, there is good news in that the Clipboard API would allow more flexibility here and there is good progress towards browser support.
Despite the good news around the Clipboard API, given the state of where things are now, in September 2020, using document.execCommand() and the paste event seems to be the way to go; the Clipboard API, as well as the corresponding permissions via the Permissions API, are still in the process of being implemented in browsers. However, most of what’s in this post will (hopefully) still be valid with the Clipboard API, with the clipboard interaction code being more robust and the more hacky bits being thrown away.
Copying to the clipboard with document.execCommand(“copy”)
Selecting plain text and copying it to the clipboard is straightforward with an <input> or <textarea>:
We can make a generic method to copy arbitrary text to the clipboard by programmatically creating a <textarea>, setting its value to the text we want, performing the above operations to copy its contents to the clipboard, and finally removing the created <textarea>.
Now, using this method, if we can serialize an object to some sort of textual format, we can put it on the clipboard. JSON is a good option, as it’s easy to work with in Javascript.
Object → JSON → Plain text → Clipboard
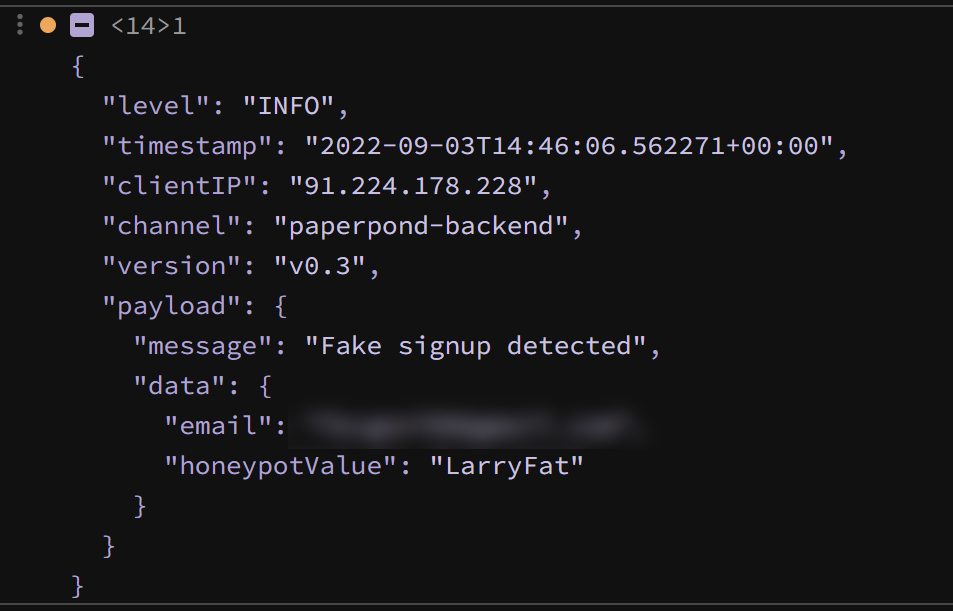
In ScratchGraph, entities like notes, connectors, etc. have a toJSON() method, which returns a JSON serialized representation of the entity, e.g.:
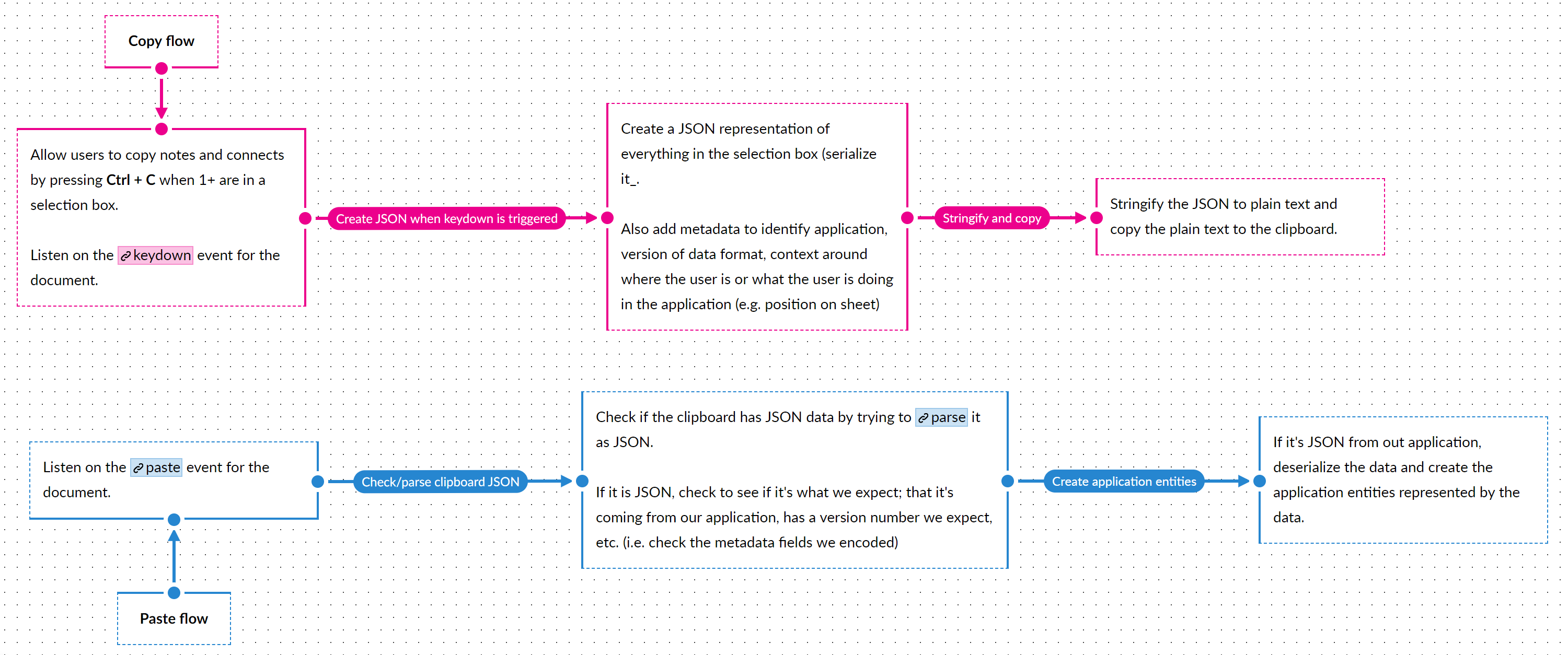
When a user initiates a request to copy something, say by hitting Ctrl + C, we iterate over all the selected entities, get the serialized JSON for each, and build an array of JSON objects. Next we construct a JSON object containing that array, along with some metadata around context (application name, version, etc.). Finally, we JSON.stringify this object to get a plain text representation and use the Clipboard.copyText() method to write to the clipboard.
To read what’s on the clipboard, we can listen for and implement a handler on the paste event.
While you can listen for the paste event on any DOM element, I’ve found it tricky to isolate to specific elements because the element that has focus isn’t always obvious and I’ve run into situations where an offscreen <input> gets focus and the clipboard content simply gets pasted into that input. It’s more reliable to listen on the document and determine if and where to paste something based on the metadata embedded when we copied data to the clipboard.
Sketching out what we need to deal with, we get the following:
Listen for paste events on the document
Check if there’s plain-text content being pasted
Try to parse the plain-text content as JSON
Check whatever metadata is in the object to see if it’s something copied from our application and it’s something we can read/interpret.
If it’s something we can handle, suppress any default behavior and do what is needed to clone and create new objects.
This is simplified for clarity, but the code in ScratchGraph looks something like this:
The createFromClipboardJson() method handles the application-specific logic of reading the data and creating copies. In ScratchGraph, I’m dealing with entities, so I don’t actually deserialize, I just read the bits of data needed to be make a clone and create something with a new ID (i.e. new entity). However, YMMV, based on the type of objects you’re dealing with, how your application handles data, and/or how you deal with state.
Limitations and future work
As I mentioned, there are limitations here when it comes to reading or writing from/to the clipboard. The paste event will only be triggered by interactions supported by the browser, so creating something like a button to paste content isn’t possible. document.execCommand("copy") is now considered obsolete and the method presented to allow copying arbitrary bits of text is pretty hacky, though it is versatile in that you can bind the method to application-specific interactions (e.g. a button to copy content). A further limitation here is that data can only be copied as plain-text and we’re not actually encoding any type information; this manifests in some non-ideal behavior, where what’s put on the clipboard can be pasted into any application that accepts plain-text.
The Clipboard API looks to be a promising solution to these limitations. I’m hoping to revisit this in the near future to update the clipboard interaction logic to use the API and have an all-round cleaner and more robust solution.
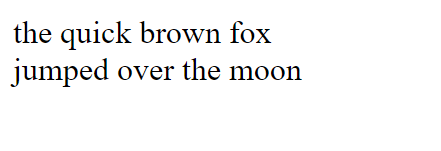


=currentPathLength+computeLength(current,n).svg)
=computeLength(n,endpt).svg)
=g(n)+h(n)-t(n).svg)
=(vecCurrentTo(endpt)-dot-vecCurrentTo(n))-times-computeLength(current,n).svg)