I began experimenting with WebGL a while back and hit a wall when it came to importing geometry data into a scene, as you can only get so far with programmatically generated cubes and spheres. I looked into an Wavefront OBJ to JSON conversion tool (to just spit out the vertices, normals, and texture coordinates of the OBJ model), but couldn’t find much. There’s a Blender plugin for Three.js, but I didn’t want a dependency on Three.js nor the Three.js JSON file format; I have nothing against either, but I didn’t want to add a thick layer of abstraction like Three.js and, honestly, I wanted to delve into the OBJ format and deal with working on geometry data at the vertex level.
The result is a simple OBJ to JSON converter written in C++. The code for the entire program is below and also available via the bitbucket repository.
One of my test models was the Clocktower model by thinice and shown below is a WebGL rendering of the converted geometry data.
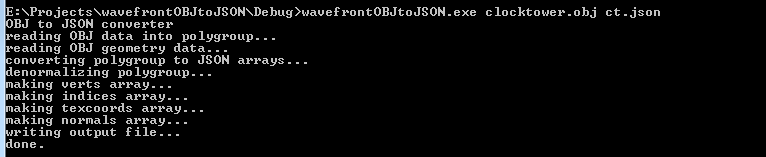
The program takes 2 arguments:
- The path of the input OBJ file
- The name of the output JSON file
Note that the converter does have some limitations:
- It will not deal with materials (i.e. it does not parse any corresponding MTL files)
- It will only parse triangle faces (no quadrilaterals). If the model has quadilaterals, you can convert them to triangles in Blender by going into Edit mode, selecting all vertices, and hitting CTRL + T.
- Named objects and polygon groups are ignored; the converter essentially treats everything in the file as a single polygon group.
#include <iostream>
#include <vector>
#include <cstdio>
struct vec2
{
public:
vec2(float _u, float _v) : u(_u), v(_v) { }
float u;
float v;
};
struct idx3
{
public:
idx3(int _a, int _b, int _c) : a(_a), b(_b), c(_c) { }
bool operator==(const idx3& other) const {
if( this->a == other.a && this->b == other.b && this->c == other.c) {
return true;
}
return false;
}
int a;
int b;
int c;
};
struct vec4
{
public:
vec4(float _x, float _y, float _z, float _w) : x(_x), y(_y), z(_z), w(_w) { }
float x;
float y;
float z;
float w;
};
struct tri
{
public:
tri(int _v1, int _v2, int _v3) : v1(_v1), v2(_v2), v3(_v3), vn1(0), vn2(0), vn3(0), vt1(0), vt2(0), vt3(0) { }
int v1;
int vn1;
int vt1;
int v2;
int vn2;
int vt2;
int v3;
int vn3;
int vt3;
};
struct polygroup
{
public:
std::vector<vec4> verts;
std::vector<vec4> normals;
std::vector<vec2> texcoords;
std::vector<tri> tris;
};
struct polygroup_denormalized
{
public:
std::vector<vec4> verts;
std::vector<vec4> normals;
std::vector<vec2> texcoords;
std::vector<int> indexbuf;
};
void echo(const char* line)
{
std::cout << line << std::endl;
}
vec4 parseVertex(const char* line)
{
char prefix[4];
float x, y, z;
sscanf(line, "%s %f %f %f", prefix, &x, &y, &z);
return vec4(x,y,z,1);
}
vec2 parseTexCoord(const char* line)
{
char prefix[4];
float u, v;
sscanf(line, "%s %f %f", prefix, &u, &v);
return vec2(u,v);
}
std::vector<int> readFace(const char* fstr)
{
std::vector<int> ret;
char buf[64];
int bufidx = 0;
for(int i=0; i<strlen(fstr); i++) {
if(fstr[i] != '/') {
buf[bufidx++] = fstr[i];
} else {
ret.push_back( atoi(buf) );
bufidx = 0;
memset(buf, 0, 64); // clear buffer
}
}
if(strlen(buf) > 0) {
ret.push_back( atoi(buf) );
}
return ret;
}
tri parseTriFace(const char* line)
{
char prefix[4];
char p1[64];
char p2[64];
char p3[64];
int v1=0, v2=0, v3=0;
int vn1=0, vn2=0, vn3=0;
int vt1=0, vt2=0, vt3=0;
sscanf(line, "%s %s %s %s", prefix, p1, p2, p3);
std::vector<int> f1 = readFace(p1);
if(f1.size() >= 1) { v1 = f1[0] - 1; }
if(f1.size() >= 2) { vt1 = f1[1] - 1; }
if(f1.size() >= 3) { vn1 = f1[2] - 1; }
std::vector<int> f2 = readFace(p2);
if(f2.size() >= 1) { v2 = f2[0] - 1; }
if(f2.size() >= 2) { vt2 = f2[1] - 1; }
if(f2.size() >= 3) { vn2 = f2[2] - 1; }
std::vector<int> f3 = readFace(p3);
if(f3.size() >= 1) { v3 = f3[0] - 1; }
if(f3.size() >= 2) { vt3 = f3[1] - 1; }
if(f3.size() >= 3) { vn3 = f3[2] - 1; }
tri ret(v1, v2, v3);
ret.vt1 = vt1;
ret.vt2 = vt2;
ret.vt3 = vt3;
ret.vn1 = vn1;
ret.vn2 = vn2;
ret.vn3 = vn3;
return ret;
}
std::vector<polygroup*> polygroups_from_obj(const char* filename)
{
bool inPolyGroup = false;
polygroup* curPolyGroup = NULL;
std::vector<polygroup*> polygroups;
FILE* fp = fopen(filename, "r");
if(fp == NULL) {
echo("ERROR: Input file not found");
return polygroups;
}
// make poly group
if(curPolyGroup == NULL) {
curPolyGroup = new polygroup();
polygroups.push_back(curPolyGroup);
}
// parse
echo("reading OBJ geometry data...");
while(true) {
char buf[2056];
if(fgets(buf, 2056, fp) != NULL) {
if(strlen(buf) >= 1) {
// texture coordinate line
if(strlen(buf) >= 2 && buf[0] == 'v' && buf[1] == 't') {
vec2 tc = parseTexCoord(buf);
curPolyGroup->texcoords.push_back(tc);
}
// vertex normal line
else if(strlen(buf) >= 2 && buf[0] == 'v' && buf[1] == 'n') {
vec4 vn = parseVertex(buf);
curPolyGroup->normals.push_back(vn);
}
// vertex line
else if(buf[0] == 'v') {
vec4 vtx = parseVertex(buf);
curPolyGroup->verts.push_back(vtx);
}
// face line (ONLY TRIANGLES SUPPORTED)
else if(buf[0] == 'f') {
tri face = parseTriFace(buf);
curPolyGroup->tris.push_back(face);
}
else
{ }
}
} else {
break;
}
}
fclose(fp);
return polygroups;
}
std::string int_array_to_json_array(const std::vector<int>& arr)
{
std::string json = "[";
for(int i=0; i<arr.size(); i++) {
char buf[256];
sprintf(buf, "%i", arr[i]);
if(i > 0) {
json.append(",");
}
json.append(buf);
}
json.append("]");
return json;
}
std::string vec4_array_to_json_array(const std::vector<vec4>& arr)
{
std::string json = "[";
for(int i=0; i<arr.size(); i++) {
char buf[64];
sprintf(buf, "%f", arr[i].x);
if(i > 0) {
json.append(",");
}
json.append(buf);
sprintf(buf, "%f", arr[i].y);
json.append(",");
json.append(buf);
sprintf(buf, "%f", arr[i].z);
json.append(",");
json.append(buf);
}
json.append("]");
return json;
}
std::string vec2_array_to_json_array(const std::vector<vec2>& arr)
{
std::string json = "[";
for(int i=0; i<arr.size(); i++) {
char buf[64];
sprintf(buf, "%f", arr[i].u);
if(i > 0) {
json.append(",");
}
json.append(buf);
sprintf(buf, "%f", arr[i].v);
json.append(",");
json.append(buf);
}
json.append("]");
return json;
}
polygroup_denormalized* denormalize_polygroup(polygroup& pg)
{
polygroup_denormalized* ret = new polygroup_denormalized();
std::vector<idx3> processedVerts;
for(int i=0; i<pg.tris.size(); i++) {
for(int v=0; v<3; v++) {
idx3 vidx(0,0,0);
if(v == 0) {
vidx = idx3(pg.tris[i].v1, pg.tris[i].vn1, pg.tris[i].vt1);
} else if(v == 1) {
vidx = idx3(pg.tris[i].v2, pg.tris[i].vn2, pg.tris[i].vt2);
} else if (v == 2) {
vidx = idx3(pg.tris[i].v3, pg.tris[i].vn3, pg.tris[i].vt3);
} else { }
// check if we already processed the vert
int indexBufferIndex = -1;
for(int pv=0; pv<processedVerts.size(); pv++) {
if(vidx == processedVerts[pv]) {
indexBufferIndex = pv;
break;
}
}
// add to buffers
if(indexBufferIndex == -1) {
processedVerts.push_back(vidx);
ret->verts.push_back(pg.verts[vidx.a]);
if(pg.normals.size() > 0) {
ret->normals.push_back(pg.normals[vidx.b]);
}
if(pg.texcoords.size() > 0) {
ret->texcoords.push_back(pg.texcoords[vidx.c]);
}
int idx = (int)ret->verts.size() - 1;
ret->indexbuf.push_back(idx);
} else {
ret->indexbuf.push_back(indexBufferIndex);
}
}
}
return ret;
}
void polygroup_to_json(polygroup& pg, const char* jsonFilename)
{
echo("denormalizing polygroup...");
polygroup_denormalized* dpg = denormalize_polygroup(pg);
echo("making verts array...");
std::string vertsStr = "";
vertsStr.append("\"verts\":");
vertsStr.append(vec4_array_to_json_array(dpg->verts));
vertsStr.append(",");
echo("making indices array...");
std::string indicesStr = "";
indicesStr.append("\"indices\":");
indicesStr.append(int_array_to_json_array(dpg->indexbuf));
indicesStr.append(",");
echo("making texcoords array...");
std::string texcoordsStr = "";
texcoordsStr.append("\"texcoords\":");
if(dpg->texcoords.size() > 0) {
texcoordsStr.append(vec2_array_to_json_array(dpg->texcoords));
} else {
texcoordsStr.append("[]");
}
texcoordsStr.append(",");
echo("making normals array...");
std::string normalsStr = "";
normalsStr.append("\"normals\":");
if(dpg->normals.size() > 0) {
normalsStr.append(vec4_array_to_json_array(dpg->normals));
} else {
normalsStr.append("[]");
}
echo("writing output file...");
FILE *fp = fopen(jsonFilename, "w");
fputs("{", fp);
fputs(vertsStr.c_str(), fp);
fputs("\n", fp);
fputs(indicesStr.c_str(), fp);
fputs("\n", fp);
fputs(texcoordsStr.c_str(), fp);
fputs("\n", fp);
fputs(normalsStr.c_str(), fp);
fputs("}", fp);
fclose(fp);
delete dpg;
dpg = NULL;
}
int main(int argc, char *argv[])
{
echo("OBJ to JSON converter");
if(argc < 3) {
echo("ERROR: Invalid arguments");
echo("ARGS: wavefrontOBJtoJSON.exe <inputFile> <outputFile>");
return 0;
}
char* inputFilename = argv[1];
char* outputFilename = argv[2];
echo("reading OBJ data into polygroup...");
std::vector<polygroup*> pg = polygroups_from_obj(inputFilename);
if(pg.size() > 0) {
echo("converting polygroup to JSON arrays...");
polygroup_to_json(*pg[0], outputFilename);
}
// cleanup
for(int i=0; i<pg.size(); i++) {
delete pg[i];
pg[i] = NULL;
}
pg.clear();
echo("done.");
return 0;
}
One notable aspect of the conversion is denormalizing the geometry [done in denormalize_polygroup()]. An OBJ file stores unique lists of vertices, normals, texture coordinates, etc. and for each face there is an index into the list of vertices, an index into the list of normals, etc. This is great when it comes to storing data (as it eliminates duplicate geometry data, and decreases the file size) but when rendering you can’t have the data organized like this, as you can only have a single index buffer, where each index corresponds to the same location within the list of vertices, normal, texture coordinates, etc. Therefore, data must be duplicated such that every combination of vertex coordinate, texture coordinate, normal, etc. is uniquely identified by an entry in the index buffer (e.g. if 2 vertices have the same position but different texture coordinates, it has to be identified by a different index in the index buffer, and the position must be duplicated so that the new texture coordinate and position can be referenced by the different index).
EDIT (11/1/2013): In the initial code committed and presented was outputting Javascript variables set equal to arrays, the code has been updated to output valid JSON data instead. Furthermore, the namespace argument for the program is no longer required and no type of namespacing is done on the output data.