Preventing fake signups
Sep 3 2022 · Application Design
The problem
One annoying problem I began encountering with ScratchGraph a while ago was fake signups. Every so often I would notice a new account created but there would be no interaction on the site beyond account creation. I’d also notice some other errors in the application log, as the spam bot would attempt to fill in and submit every form on the landing page, so I’d get login failure and reset account errors as well. At first, I figured I could just ignore this; metrics would be a bit off, I’d have a bounced welcome email from time to time, and I could just purge the few fake accounts at some point the future. Unfortunately it got to the point where there were so many fake accounts being created that figuring out if an account was real took more effort, there was a lot of garbage in the database and logs and, perhaps most importantly, welcome emails being sent out would be bounced or flagged as spam, dragging down my email reputation and increasing the possibility of emails going to spam.
A solution
There’s a bunch of blog posts from email marketing services detailing this issue, e.g. Mailchip, Folderly. There’s usually a common few solutions mentioned:
- ReCAPTCHA
- Email confirmation for new accounts
- Some sort of throttling
- Honeypot fields
I opted for honeypot fields.
- I wanted to minimize dependencies and additional integrations, so no ReCAPTCHA
- Email confirmation seemed like too heavy of a lift and I disliked the idea of having a user jump from the application to their inbox
- Throttling kinda makes sense (I could see if other forms were submitted around the same time, with the same email address, and flag the account), this is possible but not trivial for a PHP application where you don’t have service-level jobs running in the background
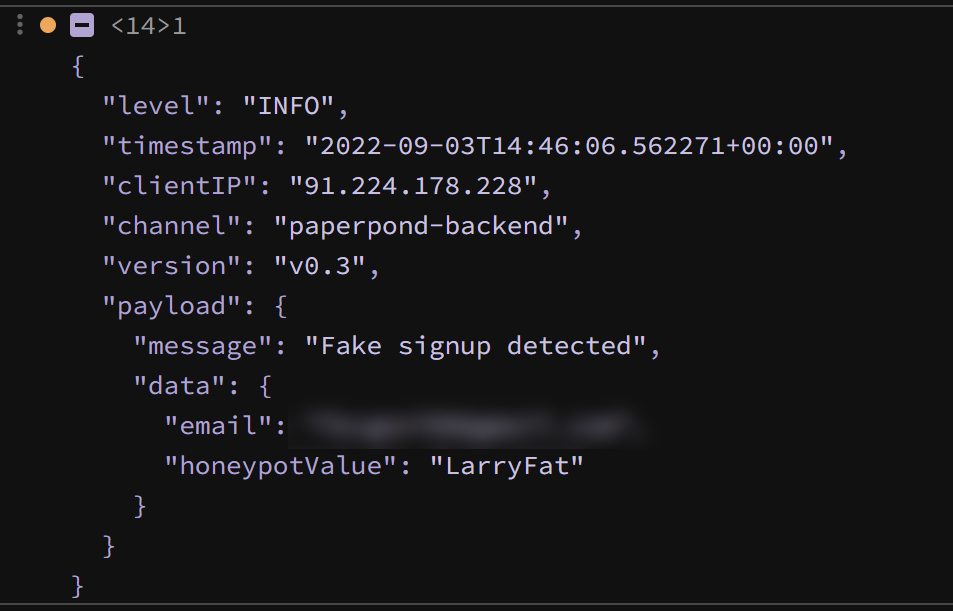
So, I added a honeypot field on the signup form. In practice, I wrapped a text input in a hidden div and I gave the input the name fullname. A user’s full name is also not requested/collected during sign up and I figured the spambot may try to gauge what to do with the field based on its name, so I should give it a realistic name. On the backend, if fullname is non-empty, the request still succeeds (HTTP 200), but an account is not created. Instead, email and IP address are logged in a table for spam signups (I figure I might be able to do something with this data at some point).
Efficacy
I was somewhat skeptical as to how well a honeypot field on the signup form would work, I was imaging spambots being incredibly sophisticated, maybe noticing the field was hidden or there was no change on the frontend. Turns out this is not the case or at least not the case for the spambots I was facing. From what I can tell, this relatively simple approach has detected and caught all fake signups from spambots.
I imagine there’s a shelf life to this solution (happy to be wrong) but, when it starts to fail, I can always integrate another approach such as throttling or ReCAPTCHA.